All About Attention
Hierarchical Attention Network for Document Classification
文章为个人理解+笔记233
Hierarchical Attention Network for Document Classification
基于层级注意力机制的文本分类模型,该模型分为两个Word2Sentence, Sentence2Document两个过程, 该过程在结构上具有相似性,都是由Encoder和Attention两个部分构成。
![]()
其中Encoder部分使用的是一个BiGRU结构,详细可查看论文。
其中加入的Attention机制。
通常Word2Sentence过程中,我们一般使用序列的最后一个GRU神经元的输出来代表整个Sentence的含义,用作该句子的上下文特征向量,该方法存在缺点,随着序列的不断增长,该向量留存位于序列前列的单词的含义。
如果序列前列单词对于该句子完整的上下文语义有重要作用,那么这个最后一个GRU神经元输出的向量就不能表征整个句子的含义。
对于Attention机制来说,目的是找出句子中已于最重要的部分,将每一个单词的输出(即每一个GRU神经元),输入到一个MLP(多层感知机中)得到结果作为一个该单词含义的隐含形式。其中 \(h_{it}表示句子i中单词t经过BiGRU之后的输出,u_{it}作为该单词含义的隐含表示\)
\[u_{it}=tanh(W_wh_{it}+b_w)\]为了衡量单词的重要性,这里用一个代表Query Pattern的随机初始化的向量与单词向量进行相似度计算,然后通过Softmax进行归一化操作,得到Attention的权重矩阵。(这里很多Blog中写道这个随机初始化向量代表的是上下文含义,但该向量并不是对于某个特定的句子来说的,对于每一个Sentence来说,这个向量是相同的,通过训练网络的过程学习得到,我更倾向于将其理解为一种Pattern,类比CNN中的Kernal所学到的特征,在Attention的 Key-Query-Value模型中,该向量作为Query,我们可以将其当作一个询问的高级表示,比如“该词是否含有比较重要的信息”)
\[\alpha_{it}=\frac{exp(u_{it}^Tu_w)}{\sum_texp(u_{it}^Tu_w)}\] \[其中u_w 为随机初始化的向量,代表Query \ Pattern\]得到Attention 权重矩阵之后,句子向量可以看作是这些词向量的加权求和。
\[s_i=\sum_t \alpha_{it}h_{it}\]Transformer
Transformer结构图
![]()
Self-Attention
自注意力机制是提出Transformer的论文《Attention is all you need》 中提出的观点,对于Transformer的结构的理解有着非常重要的作用。
论文中提到了一个Key-Query-Value的Attention模型,其中认为注意力函数能被描述为一个Query以及key-Value对的映射。计算的结果是Value值的加权求和,对于每个Value值对应的权重,是由相对应的Key和Query经过一个复杂的函数得来的。
如果用Q,K,V矩阵代表Key,Query,Value对于一个Self-Attention 矩阵来说,就是Q(Query),K(key),V(Value)三个矩阵均来自同一矩阵的映射,但是映射矩阵是不同的,映射矩阵属于需要训练的参数
以Scaled Dot-Product Attention为例
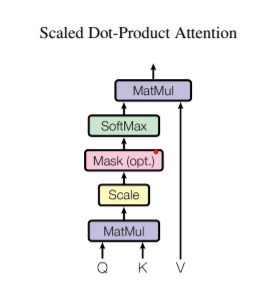
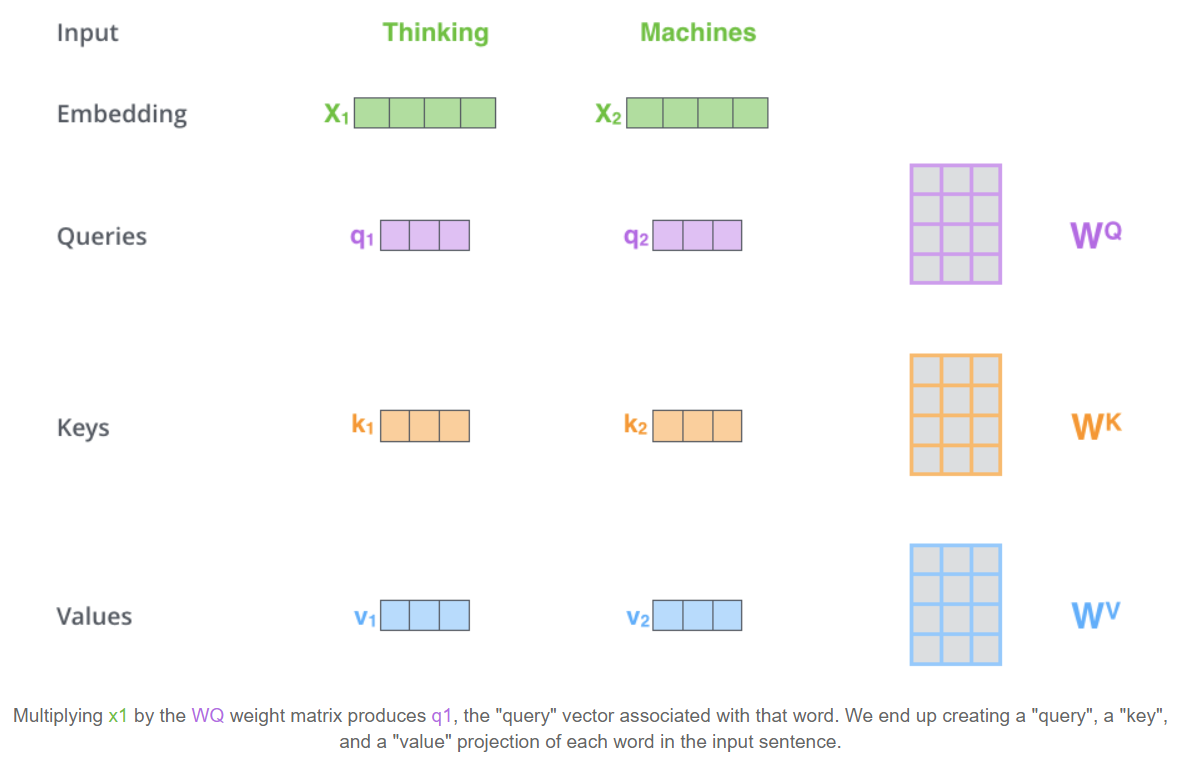
下面是一个实际的例子,加深对于Q,K,V矩阵来历的理解,来源
下面按照Scale Dot-Product Attention,对Thinking 的词向量进行计算。
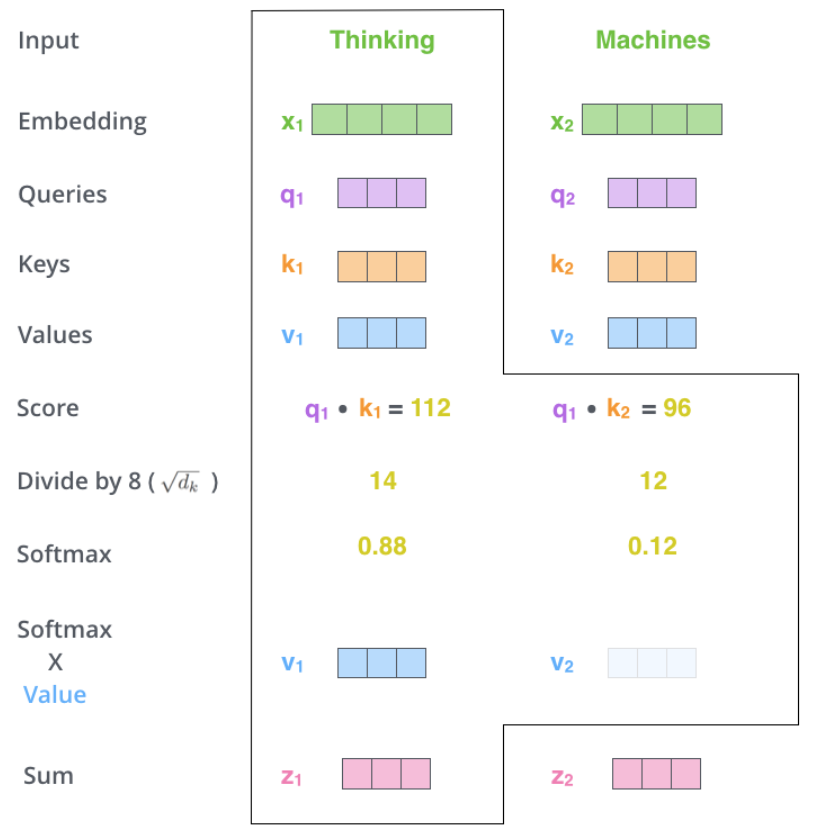
如果理解了HAN中Attention的计算方法,进行类比,这个计算过程不算困难,对于我来说,最难理解的是Query,Key,Values如何得来的。
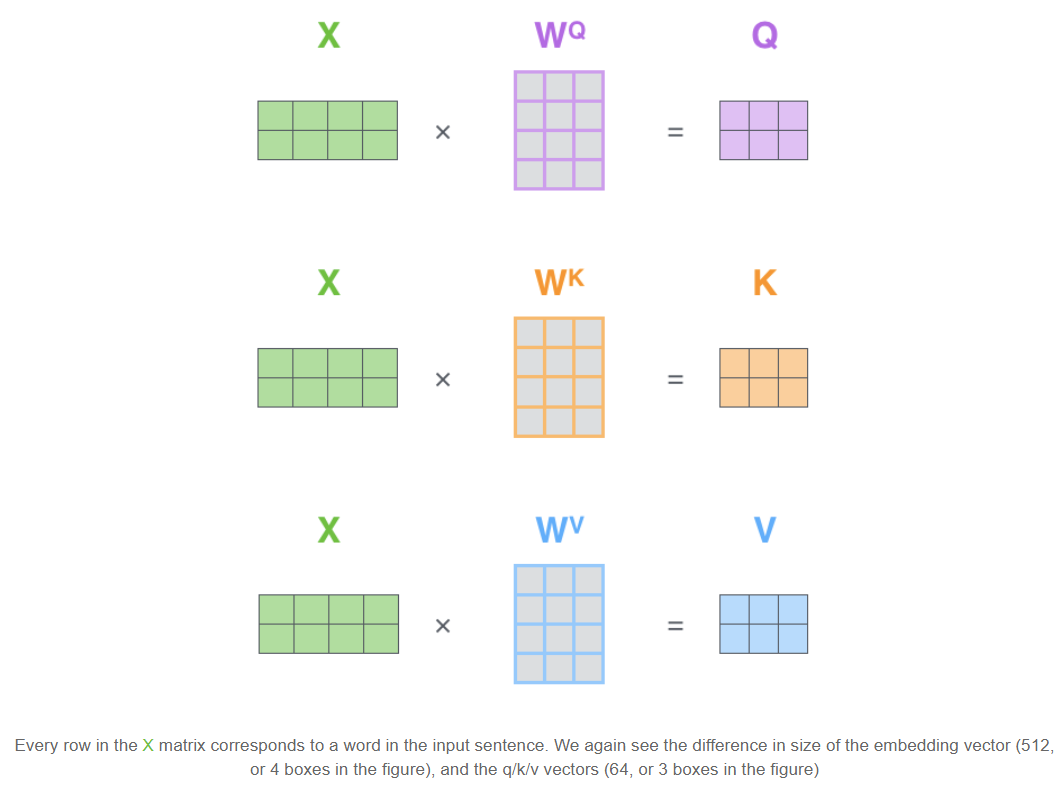
X矩阵为对于多个词向量的打包,可以看到Q,K,V都是通过X经过映射函数Wq,Wk,Wv转换而来,而这种Q,K,V都是通过同一矩阵进行映射的及Self-Attention。其中Wq,Wk,Wv是网络中的参数,通过训练得到。
Multi-Head Attention
在理解Multi-Head Attention的过程中,我想到了CNN卷积神经网络中Kernal的概念,在CNN处理图像的过程中,每一个卷积核在训练之后都是对某一类Feature Pattern的一种提取,例如提取曲线,直角,横线等。在Transformer中,我也将Wq,Wk,Wv这一组映射矩阵理解为一个Kernal,用来提取单词结合了上下文之后的信息。在CNN中,通常有多个卷积核来提取特征,同样在Self-Attention的过程中,对于一个Word来说,多组(Wq,Wk,Wv)也可以提取出不同的Pattern。然后将这些不同的Attention出来的结果进行一个拼接(Concatation),作为下一个Encoder的输入。
论文中这样写到
Multi-head Attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.
\[MultHead(Q,K,V)=Concat(head_1,...,head_h)W^O \\ Where \ head_i=Attention(QW_i^Q,KW_i^K,VW_i^V)\]
在论文中h=8。
完整的过程
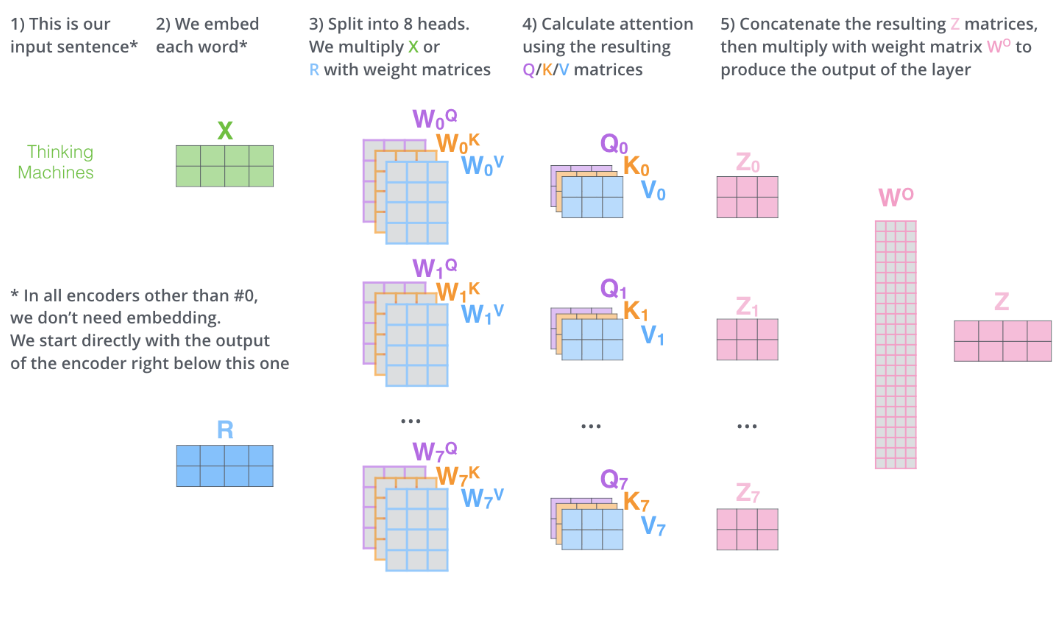
需要注意的是,在最后经过8个Head Attention之后得到Z0,Z1…Z7之后,拼接成Z后,要与Wo相乘才能得出self-Attention层的输出。在构建过程中,与Wo矩阵相乘容易漏掉。Wo为网络结构的参数,训练得到。
Position-wise Feed-Forward Network
在一个Encoder 模块中,除了Self-Attention的sub-layer,还存在一个全连接的前向网络(Fully Connected feed-forward network),它包含两个线性层,中间通过ReLU激活函数
\[FFN(x)=max(0,xW_1+b_1)W_2+b_2\]从Encoder的结构图中还可以看到,Self-Attention layer 和 Feed-Forward layer之后都增加了一个Residual layer 和 Normalization layer。 Residual Layer 通过将前一层的信息无差别的传递到下一层,可以有效的仅关注差异部分,解决深度网络训练困难问题。Normalization layer,通过对Residual layer之后的结果的归一化,可以加速模型训练过程,使其更快收敛。
\[output=LayerNorm(x+sublayer(x))\]Decoder
整个的Decoder模块由三个Sub-Model组成,第一个是一个masked-multi-head Attention,在该模块中Key,Query,Value均来自已经输出词向量,加入了Mask操作,即只能attend到已经翻译过的词语。
第二层的Masked-Multi-Head Attention layer中,只有Query来自前一层Masked-Multi-Head-Attention的输出,Key和Value来自Encoder的输出。
第三个Sub-Model就是一个全连接的前向网络(Feed-Forward Network)。
Positional Encoding
对于Transfomer来说,Sentence中的语序并没有很大的意义,因为该模型更多的像一个词袋模型,因此为了将语序的含义加入进去,Google顶一个一个位置编码函数,这个位置编码有着与词向量相同的维度,因此两个向量可以相加。
至于为什么用这样一个Positionl Encoding Function,我也没有弄懂。
Summary
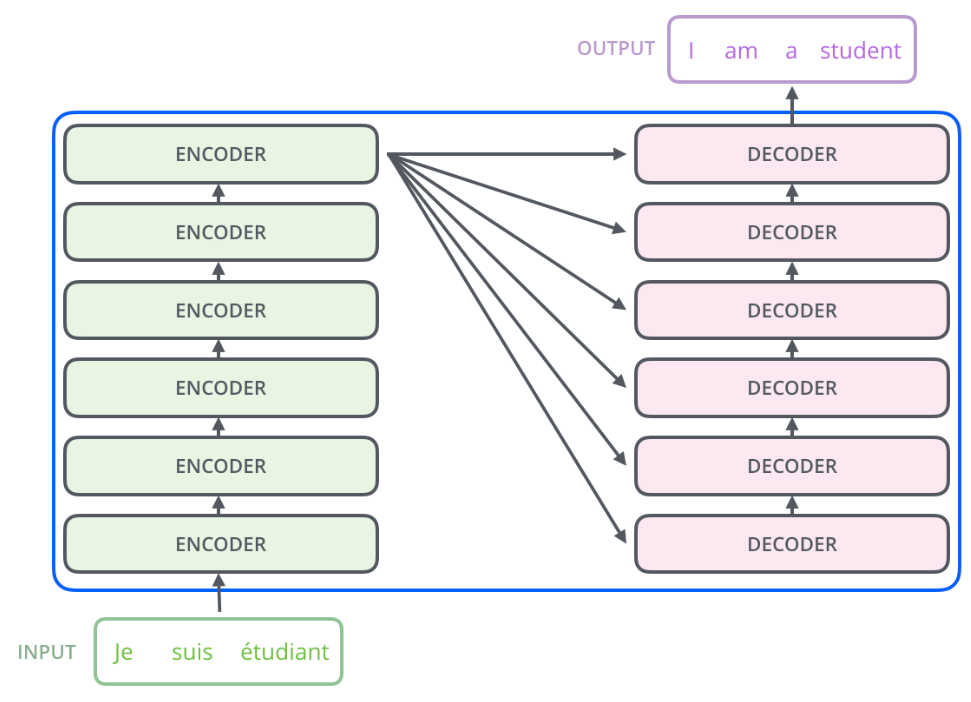
完整结构就是论文中的第一张图,可以看到整个Transfomer是由6个Encoder,6个Decoder堆叠而成的。样例路径
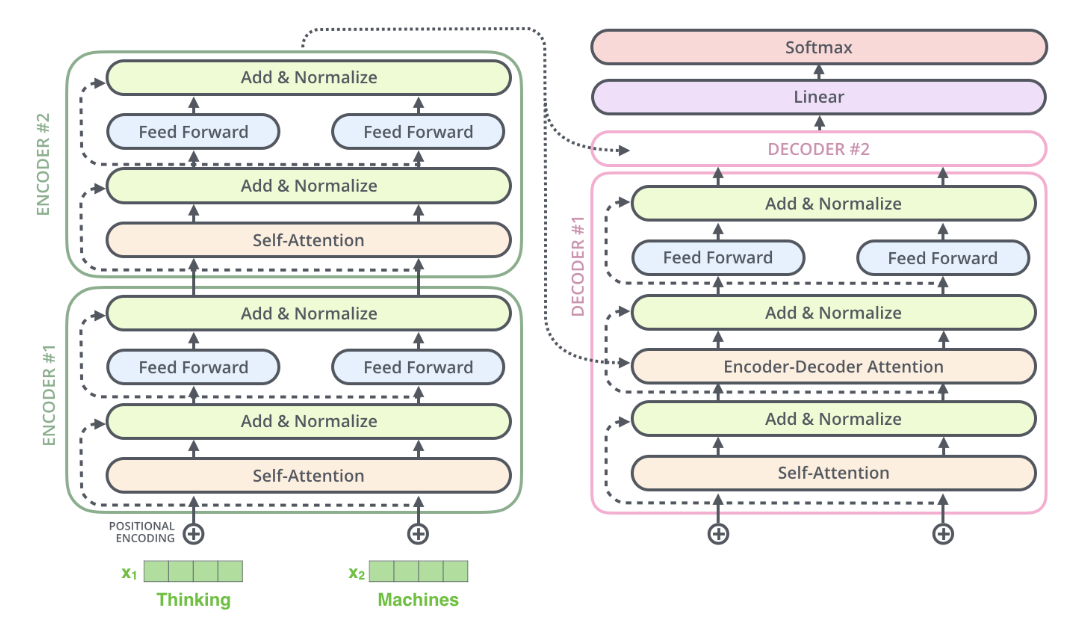
每个Encoder都结构相同,但是不共享权重,每个全连接层也都是独立的权重。
self-Attention 例子:
假设我们有一个要翻译的句子:
“The animal didn’t cross the street because it was too tired”
it 指的是street 还是 animal?这对机器来说没那么容易,我们要做的就是在用transformer 处理 it 时, self-attention 会让 it 与 animal 相关联。
在结构的最后是一个线性层和一个Softmax层
线性层是个简单的全连接层,将解码器的最后输出映射到一个非常大的logits向量上。假设模型已知有1万个单词(输出的词表)从训练集中学习得到。那么,logits向量就有1万维,每个值表示是某个词的可能倾向值。
softmax层将这些分数转换成概率值(都是正值,且加和为1),最高值对应的维上的词就是这一步的输出单词。
Note
Self-Attention 和Seq2Seq Attention相比,优越性在哪
RNN本身对于长距离的依赖关系有一定的捕捉能力,但是由于序列模型是通过门控单元是的信息保持流动,并且选择性地传递信息。但这种方式在文本长度越来越长的条件下,捕捉依赖关系的能力越来越低,因为每一次递归都伴随着信息的损耗,所以Attention机制来增加我们所关注的那部分依赖关系的捕捉。除此之外,序列模型也不能对层次结构的信息尽心有效的表达。
Attention模型本身的优点(相较于RNN)
- 对长期依赖关系有着更强的捕捉能力
- 可以并行计算
CNN模型可以被看作是N-Gram的Detector,N-Gram的n对应CNN卷积核的大小。CNN基于的假设是局部信息存在相互依赖关系,二卷积和可以把这类依赖关系以类似N-Gram的形式提取出来。在我自己的理解中,Self-Attention的思想更多的是借鉴了CNN中的概念 。
Self-Attention advantages:
- Constant path length between any two positions
- Variable-sized perceptive field
- Gating/multiplication enables crisp error propragation
- Trivial to parallelize