MapReduce Programming Example
Author: Zreal 曾令泽
Student_ID: 1120162062
Platform: MAC OS
Introduction To Mapreduce API
连接hdfs
1
2
3
4
5
6
7
private static Configuration conf = new Configuration();
private static String locpath = "hdfs://localhost:9000";
private static void init() throws Exception {
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("dfs.replication", "1");
}
Map类继承Mapper
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public static class Map extends Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>{
@override
public void map(KEYIN key, VALUEIN value,Context context) throws IOException, InterruptedException {
/*
处理逻辑
contextr.write((KEYOUT)key,(VALUEOUT)value)
*/
}
}
}
/*
其中
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>{}
出入都是键值对的形式,规范其类型
方法map 继承了Mapper ,对其进行override
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
*/
Reduce类继承Reducer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public static class Reduce extends Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
@override
public void reduce(KEYIN key,Iterable<VALUEIN> values,Context context) throws IOException,InterruptedException{
/*
处理逻辑
context.write((KEYOUT) key,(VALUEOUT) value);
*/
}
}
/*
public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>{}
出入都是键值对的形式,规范其类型
方法reduce 继承Reducer, 对其进行override
protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context
) throws IOException, InterruptedException {
for(VALUEIN value: values) {
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
*/
Job 调度管理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
// String InputDir = locpath + "/test/WordCountInput";
// String OutputDir = locpath + "/test/WordCountOutput";
Job job = Job.getInstance(conf, "Wordcount");
//获取job实例
/*
Creates a new {@link Job} with no particular {@link Cluster} and a given jobName.A Cluster will be created from the conf parameter only when it's needed.
*/
job.setJarByClass(WordCountOfFile.class);
/*
Set the Jar by finding where a given class came from
*/
job.setMapperClass(Map.class);
//Set the Mapper for the job.
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
/*Set the key and value class for the map output data. This allows the user to
specify the map output key and value class to be different than the finaloutput value class.*/
job.setCombinerClass(Combiner.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 同上map
// job.setSortComparatorClass(IntWritableDecreasingComparator.class);
// IntWritableDecreasingComparator 是自定义函数,可以指定value降序排列
FileInputFormat.addInputPath(job, new Path(InputDir));
FileOutputFormat.setOutputPath(job, new Path(OutputDir));
// 出入路径指定
System.exit(job.waitForCompletion(true)?0:1);
//Submit the job to the cluster and wait for it to finish.
// return true if succeed
// parameter true means print the process to the user
Rquirement one
编程实现文件合并和去重操作
编写 MapReduce 程序,实现对多个文件的合并,并剔除其中重复的内容,去重后的内容输出到一个新的文件。
Practice one
思路
以每一行为一个最小重复单元,每一行作为一个Key值,不需value。
map对每一份文件的每一行做操作,因为key值是唯一的,reduce操作中就将进行了合并盒去重操作
Coding
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
/**
* @program: LAB3_MapReduceExample
* @description:
* @author: E1ixir_zzZ
* @create: 2019-05-20 14:30
**/
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hdfs.server.namenode.Content;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.OutputFormat;
import org.apache.hadoop.mapreduce.InputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.FileOutputStream;
import java.io.IOException;
public class MergyAndDeduplication {
private static Configuration conf=new Configuration();
private static String locpath="hdfs://localhost:9000";
private static void init() throws Exception{
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("dfs.replication","1");
}
public static class Map extends Mapper<Object,Text,Text,Text>{
private Text text=new Text();
public void map(Object key,Text value, Context context)throws IOException,InterruptedException{
text=value;
context.write(text,new Text(""));
}
}
public static class Reduce extends Reducer<Text,Text,Text,Text>{
public void reduce(Text key,Iterable<Text> values, Context context) throws IOException,InterruptedException{
context.write(key,new Text(""));
}
}
public static void main(String [] args) throws Exception{
init();
String InputDirPath=locpath+"/test/Input";
String OutputDirPath=locpath+"/test/Output";
Job job=Job.getInstance(conf,"MergeAndDepulicated");
job.setJarByClass(MergyAndDeduplication.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job,new Path(InputDirPath));
FileOutputFormat.setOutputPath(job,new Path(OutputDirPath));
System.exit(job.waitForCompletion(true)?0:1);
}
}
Result

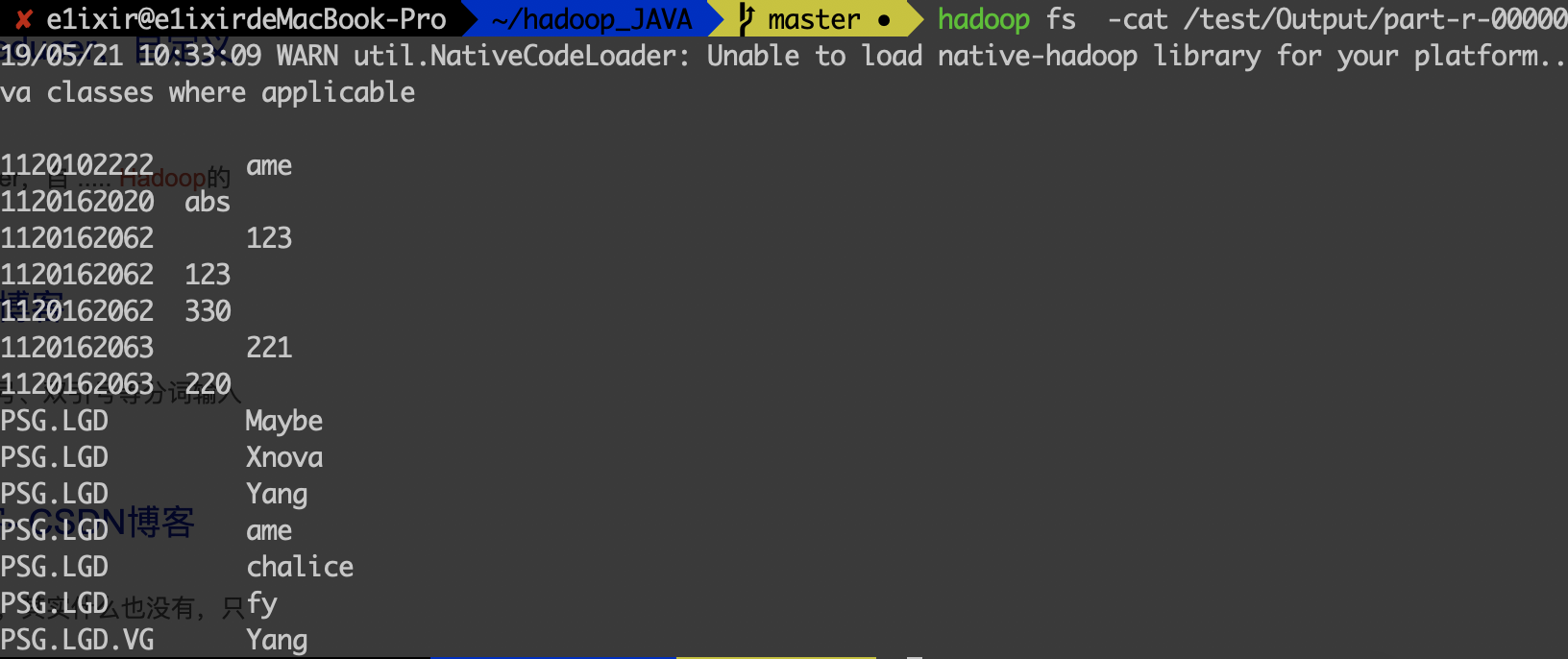
Requirement two
编程实现倒排索引 编写 MapReduce 程序,实现对多个输入文件的内容建立倒排索引,输出单词到文档的映射关系及单词在该文档中的出现次数。
Practice two
思路
参考:
https://blog.csdn.net/yeruby/article/details/40981561
整个过程经过了一次map,一次combine,一次reduce
Mapper Input:<Object,Text,Text,Text>
Mapper Output:
KEY: “word1 : file1” / VALUE:”1”
KEY: “Word2 : file4” / VALUE:”1”
Combiner Input:
KEY: “word1 : file1” / VALUE:”1”
KEY: “Word2 : file4” / VALUE:”1”
Combiner Output:
KEY: “word1” / VALUE:”file1: word1_number”
KEY: “Word2” / VALUE:”file4: word2_number”
Reducer Input:
KEY: “word1” / VALUE:”file1: word1_number_infile1”
KEY: “Word2” / VALUE:”file4: word2_number_infile4”
Reducer Output:
KEY:”word1” / VALUE:”file1:word1_number_infile1;file2:word1_number_infile2;file3:word1_number_infile3”
KEY: “Word2” / VALUE:”file4: word2_number_infile4; file1:word2_number_infile2”
Coding:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
import com.jcraft.jsch.IO;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
/**
* @program: LAB3_MapReduceExample
* @description: 统计每个文件下的词频,并逆序输出
* @author: E1ixir_zzZ
* @create: 2019-05-20 18:53
**/
public class WordCountOfFile {
private static Configuration conf = new Configuration();
private static String locpath = "hdfs://localhost:9000";
private static void init() throws Exception {
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("dfs.replication", "1");
}
public static class Map extends Mapper<Object, Text, Text, Text> {
private Text valueInfo = new Text("1");
private Text keyInfo = new Text();
private FileSplit split;
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
split = (FileSplit) context.getInputSplit();
StringTokenizer stk = new StringTokenizer(value.toString());
while (stk.hasMoreElements()) {
String filename = split.getPath().getName();
String word = stk.nextToken()+":"+filename;
keyInfo.set(word);
context.write(keyInfo, valueInfo);
}
}
}
public static class Combiner extends Reducer<Text,Text,Text,Text>{
private Text outKey=new Text();
private Text outValue=new Text();
public void reduce(Text key,Iterable<Text> values,Context context)throws IOException, InterruptedException{
int sum=0;
for(Text value:values){
sum+=Integer.parseInt(value.toString());
}
int SplitIndex=key.toString().indexOf(':');
outKey.set(key.toString().substring(0,SplitIndex));
String v=key.toString().substring(SplitIndex+1)+":"+Integer.toString(sum);
System.out.println(v);
System.out.println("***************");
outValue.set(v);
context.write(outKey,outValue);
}
}
public static class Reduce extends Reducer<Text,Text, Text, Text> {
public void reduce(Text key,Iterable<Text> values,Context context) throws IOException,InterruptedException{
StringBuffer string =new StringBuffer();
for(Text val:values){
string.append(val+";");
}
// System.out.println("kkk");
context.write(key,new Text(string.toString()));
}
}
public static class IntWritableDecreasingComparator extends IntWritable.Comparator {
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
@Override
public int compare(Object o1, Object o2) {
return -super.compare(o1, o2);
}
}
public static void main(String[] args) throws Exception {
init();
String InputDir = locpath + "/test/WordCountInput";
String OutputDir = locpath + "/test/WordCountOutput";
Job job = Job.getInstance(conf, "Wordcount");
job.setJarByClass(WordCountOfFile.class);
job.setMapperClass(Map.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setCombinerClass(Combiner.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// job.setSortComparatorClass(IntWritableDecreasingComparator.class);
FileInputFormat.addInputPath(job, new Path(InputDir));
FileOutputFormat.setOutputPath(job, new Path(OutputDir));
System.exit(job.waitForCompletion(true)?0:1);
}
}
Result

Requirement Three
编程实现对输入文件的排序 现有多个输入文件,每个文件中的每行内容均为一个整数。要求编写 MapReduce程序读取所有文件中的内容,进行升序排序后,输出到一个新的文件中,输出的数据格式为每行两个整数,第一个数字为第二个整数的排序位次,第二个整数为原待排列的整数,注意相同数据不合并,示例如下:

Practice Three
思路:
Map到Reduce的过程中,Mapreduce会自动按照key值的大小进行排序
Mapper:
<KeyOut,ValueOut>: <30,1> ,<32,1>,<32,1>,<33,1><31,1><32,1>
Reduce:
<KeyIn,ValueIn>:<30,[1]>,<32,[1,1,1]>,<31,[1]>
Reduce 类中维护一个lineNum来记录数据的rank,便利每一个Iterate<>Values,里面的每一个值具有同样的value,因此rank数相同, 每一次Reduce函数处理一个Key值,lineNum记录的rank+1。
<KeyOut,ValueOut>: <1,30>,<2,31>,<3,32>,<3,32>,<3,32>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
/**
* @program: LAB3_MapReduceExample
* @description:将不同文件下的数字进行排序输出到同一文件下
* @author: E1ixir_zzZ
* @create: 2019-05-23 11:07
**/
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hdfs.server.namenode.Content;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.OutputFormat;
import org.apache.hadoop.mapreduce.InputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class SortTheNumberOfFiles {
private static Configuration conf = new Configuration();
private static String locpath = "hdfs://localhost:9000";
private static void init() throws Exception {
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("dfs.replication", "1");
}
public static class Map extends Mapper<Object,Text,IntWritable,IntWritable>{
IntWritable keyInfo=new IntWritable();
IntWritable valueInfo=new IntWritable(1);
public void map(Object key, Text value,Context context)throws IOException,InterruptedException {
String line=value.toString();
FileSplit split=(FileSplit)context.getInputSplit();
String filename=split.getPath().getName();
// System.out.println("kkkk: "+line+" "+filename);
if(!(line==null || "".equals(line))){
// System.out.println(line+" "+filename);
keyInfo.set(Integer.parseInt(line));
context.write(keyInfo,valueInfo);
}
}
}
public static class Reduce extends Reducer<IntWritable,IntWritable,IntWritable,IntWritable>{
public IntWritable linenum= new IntWritable(1);
public void reduce(IntWritable key,Iterable<IntWritable> values,Context context)throws IOException,InterruptedException{
for(IntWritable value:values){
IntWritable keyInfo=linenum;
context.write(keyInfo,key);
}
linenum=new IntWritable(linenum.get()+1);
}
}
public static void main(String [] args)throws Exception{
init();
String InputDir=locpath+"/test/SortInput";
String OutputDir=locpath+"/test/SortOutput";
FileSystem hdfs=FileSystem.get(conf);
if(hdfs.exists(new Path(OutputDir))){
hdfs.delete(new Path(OutputDir),true);
}
Job job=Job.getInstance(conf,"Sort");
job.setJarByClass(SortTheNumberOfFiles.class);
job.setMapperClass(Map.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(Reduce.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputKeyClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path(InputDir));
FileOutputFormat.setOutputPath(job,new Path(OutputDir));
System.exit(job.waitForCompletion(true)?0:1);
}
}
Requirement Four
问题
编写 MapReduce 程序,实现对输入文件中的 child-parent 关系进行挖掘, 输出 grandchild-grandparent 的对应关系表。
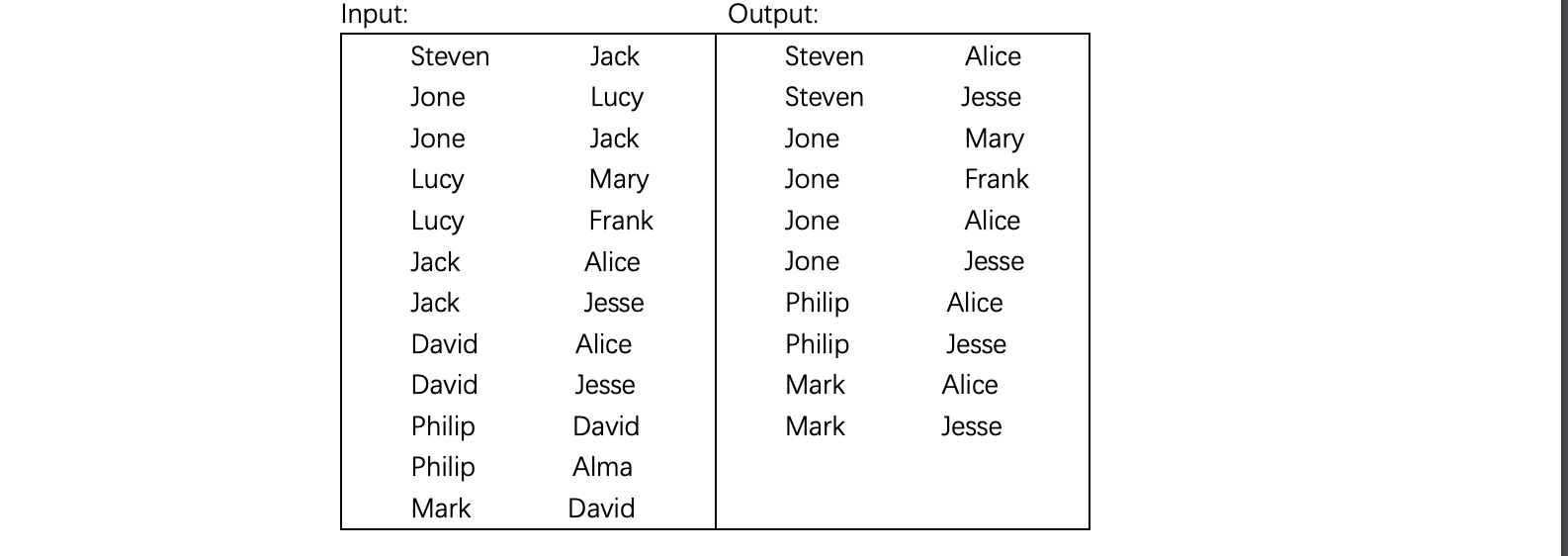
Practice Four
思路:
Grandchild 和 Grandparent中唯一的链接就是parents,我们将每一个人的父辈和子辈进行记录,遍历人群的时候,便利这个人的父辈关系和子辈关系,储存到父辈和子辈的数组里,然后再分别遍历这两个数组,每个父辈都是每个子辈的Grandparents
Map:
1代表,Key的子辈,2代表Key的父辈
<KeyOut,ValueOut>:
<”Steven”,”2_Jack”> <”Jack”,”1_Steven”><”Lucy”,”1_Jone”><”Jone”,”2_Lucy”><”Jone”,”2_Jack”><”Jack”,”1_Jone”>
Reduce:
<KeyIn,ValueIn>:
<”Steven”,[“2_Jack”]> <”Jack”,[“1_Jone”,”1_Steven”,”2_Alice”,”2_jesse”]>…
对每个人遍历,通过起关系找到存在的GrandKid-GrandParents关系
<KeyOut,ValueOut>:
<”Steven”,”Alice”>…
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.StringTokenizer;
/**
* @program: LAB3_MapReduceExample
* @description:
* @author: E1ixir_zzZ
* @create: 2019-05-27 08:19
**/
public class ChildAndParents {
private static Configuration conf = new Configuration();
private static String locpath = "hdfs://localhost:9000";
private static void init() throws Exception {
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("dfs.replication", "1");
}
public static class Map extends Mapper<Object,Text,Text,Text>{
public void map(Object Key, Text value, Context context) throws IOException,InterruptedException{
String line=value.toString();
String[] words=line.split(" ");
System.out.println(words.length);
String parents=words[1];
String child=words[0];
System.out.println("*****************\n"+parents+"___"+child);
String relationType="1";
context.write(new Text(parents),new Text(relationType+"_"+child));
relationType="2";
context.write(new Text(child),new Text(relationType+"_"+parents));
}
}
public static class Reduce extends Reducer<Text,Text,Text,Text>{
public void reduce(Text key, Iterable<Text> values,Context context)throws IOException,InterruptedException{
List<String> GrandParent=new ArrayList<String>(0);
List<String> GrandKid=new ArrayList<String>(0);
for(Text value: values){
String line=value.toString();
String type=line.split("_")[0];
String name=line.split("_")[1];
if("1".equals(type)){
GrandKid.add(name);
}
else{
GrandParent.add(name);
}
}
for(String grandkid:GrandKid){
for(String grandparent:GrandParent){
context.write(new Text(grandkid),new Text(grandparent));
}
}
}
}
public static void main(String [] args)throws Exception{
init();
String InputDir = locpath + "/test/ChildParentInput";
String OutputDir = locpath + "/test/ChildParentOutput";
FileSystem hdfs=FileSystem.get(conf);
if(hdfs.exists(new Path(OutputDir))){
hdfs.delete(new Path(OutputDir),true);
}
Job job=Job.getInstance(conf,"ChildAndParent");
job.setJarByClass(ChildAndParents.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job,new Path(OutputDir));
FileInputFormat.addInputPath(job,new Path(InputDir));
System.exit(job.waitForCompletion(true)?0:1);
}
}
Problem
ONE
Mapreduce 新旧API混淆
Hadoop 1.x 版本的包一般是mapreduce
Hadoop 0.x 版本的包一般是marped
在import的时候需要注意,否则混淆后后面会报错
具体详细参考:
https://www.cnblogs.com/sunddenly/p/3997836.html
本人遇到的错误主要是在驱动代码MAIN方法的不同上
旧API 要定义JobConf,新API直接定义Job即可
Two
Combiner 输入输出类型的问题
在practice 2中 刚开始的输出输出如下
Mapper<Object, Text,Text,IntWritable>
Combiner<Text,IntWritable,Text,Text>
Reduce <Text,Text,Text,Text>
这样在执行过程中会报错:
wrong value class: class org.apache.hadoop.io.Text is not class org.apache.hadoop.io.IntWritable
参考:https://stackoverflow.com/questions/30546957/wrong-value-class-class-org-apache-hadoop-io-text-is-not-class-org-apache-hadoo
解释:
Output types of a combiner must match output types of a mapper. Hadoop makes no guarantees on how many times the combiner is applied, or that it is even applied at all. And that’s what happens in your case.
Values from map (
<Text, IntWritable>) go directly to the reduce where types<Text, Text>are expected.
在执行过程中Hadoop不能保证有几层combiner被应用了,所以应给map的输入输出类型应该对应reduce的输入输出类型