基于移动端用户行为数据的分析及挖掘
Author: Zreal
工作概述
整个对数据的分析及挖掘大概分为一下几个步骤,每个步骤简介,下文会有每个步骤的详细介绍
数据探索及过滤
拿到的是两个数据集,一个是用户行为数据,一个是商品数据,前者有2000条数据项,后者有60w条目录项,前者是我们数据挖掘的重点.显然这样庞大的数据集以现在所拥有的硬件水平是不足以支撑我们对整个数据集进行操作的.另一方面来说,对于用户行为,有很多数据是没有用处的数据.要对这个数据集进行初步的清理.
数据可视化及确定挖掘方法
在初步的清理后,用户行为数据被减少到了110万条数据,实验要求是最后对应用户进行物品的推荐,因为有推荐这个关键词,自然会想到利用已有的成熟的推荐算法如:基于内容的推荐,基于用户的推荐,协同过滤推荐算法等等.在用协同过滤进行尝试后,发现针对这样一个数据集利用传统的推荐算法对硬件要求是很高的,数据集中的用户经筛选有2w个用户,这样我们要维护的是一个2w*60w的一个用户-物品矩阵,而且每次修改都在遍历该矩阵.最后放弃了传统的推荐算法,在分析一些数据后,发现可以用机器学习来对某天某用户的推荐物品情况进行预测.
特征提取工程
该步骤,在完成整个实验之后,个人认为是最为困难,也是最为重要的一个步骤,因为用户数据集的特殊性(每一次用户行为为一个数据项),原始数据集上基本没有可以直接来使用的特征,最后在原始数据集上进行合并,整理,统计得到基础特征,然后利用基础特征进行组合得到更多的特征.该数据中我们提取了32个特征(虽然还远远不够)进行训练.在下文将详细介绍特征提取工程
利用分类模型进行训练
相比与上一个步骤,这个步骤相对于简单,在青苔大数据分析平台上进行,采用了SVM分类器,GDBT树,logestic回归,随机森林进行了分类,然后对模型进行按权组合得到最后的分类模型.
前人工作
个人认为这个数据集的难点在于,对于大数据的探索和过滤和对于特征的提取以及在分析问题思路上的难点,针对这三个方面,我们分别借鉴了前人的思想:
主要流程根据下面的博客来进行:
https://pnyuan.github.io/blog/
大数据的探索和过滤
借鉴了很多前人的对数据的探索
发现了双12时期的数据异常,
发现了前一天的交互信息对当天的购买行为影响最大
发现了很多用户可能不是真实用户,可能是网络爬虫,需要对用户进行筛选.
(这些信息都将在之后的数据可视化环节展示)
分析问题思路:
基于简单规则的预测
参考以下两篇博文
该博主就是利用传统推荐算法,基于简答规则来进行预测.该博主假设了一个强关联,即加购物车和购买之间有强关联,于是提出了这样一条规则
在T时间内加购物车的用户最终会选择购买
最后得到的F准确率0.045,并不算高,但是也取得了一定效果.
基于机器学习的预测
参考以下博文
https://blog.csdn.net/livan1234/article/details/83024772
用机器学习来进行预测是对于该数据集的主流解决方法,最后我们也选择的这个方法对数据进行预测
特征的提取
参考以下博文:
该博主构建了约100多个特征,我们进行了参考,根据我们的能力进行了筛选决定了33个特征来构建训练集.
算法介绍
将问题转化成机器学习二分类问题后我们利用了一下4种分类算法,还利用了模型融合的算法
(不可能详细介绍每一种算法的详细推倒,所以一下内容对算法进行简介,同时介绍算法的特点)
分类算法:
逻辑回归(Logestic Regression):
简介:
逻辑回归(Logistic Regression)是一种用于解决二分类(0 or 1)问题的机器学习方法,用于估计某种事物的可能性。比如某用户购买某商品的可能性,某病人患有某种疾病的可能性,以及某广告被用户点击的可能性等。
LR在线性回归的基础上引入Sigmoid映射函数,引入了非线性因素,通常被用来处理0/1二分类问题
逻辑回归公式:
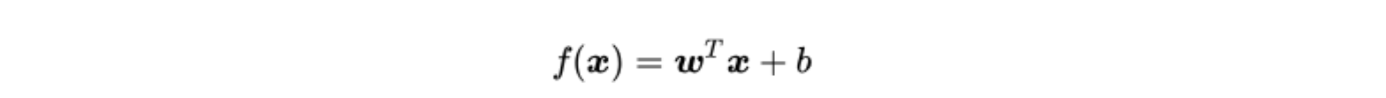
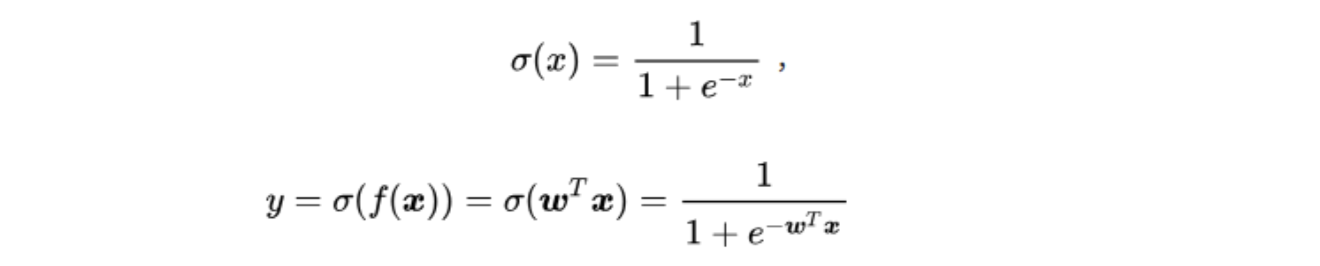
训练过程中定义损失函数利用梯度下降法进行训练
支持向量机(SVM(线性核))
简介:
支持向量机(Support Vector Machine,常简称为SVM)是一种监督式学习的方法,可广泛地应用于统计分类以及回归分析。支持向量机属于一般化线性分类器,这族分类器的特点是他们能够同时最小化经验误差与最大化几何边缘区,因此支持向量机也被称为最大边缘区分类器。
支持向量机将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面,分隔超平面使两个平行超平面的距离最大化。假定平行超平面间的距离或差距越大,分类器的总误差越小。
特点:
• 避免维数灾难,支持向量机的最终决策由少数支持向量所决定.
• 具有很好的”鲁棒性”,增删非支持向量机样本对模型没有影响,在有些应用中,SVM对选取的核不敏感
• SVM对于大规模训练样本难以实施,算法复杂度高
• SVM解决多酚类问题存在困难(这个缺点在本问题中不存在,本问题为二分类问题)
随机森林(Random Forest)
简介:
随机森林是一种集成算法(Ensemble Learning),它属于Bagging类型,通过组合多个弱分类器,最终结果通过投票或取均值,使得整体模型的结果具有较高的精确度和泛化性能。其可以取得不错成绩,主要归功于“随机”和“森林”,一个使它具有抗过拟合能力,一个使它更加精准。
Bagging算法:
Bagging也叫自举汇聚法(bootstrap aggregating),是一种在原始数据集上通过有放回抽样重新选出k个新数据集来训练分类器的集成技术。它使用训练出来的分类器的集合来对新样本进行分类,然后用多数投票或者对输出求均值的方法统计所有分类器的分类结果,结果最高的类别即为最终标签。此类算法可以有效降低bias,并能够降低variance。
在随机森林中:
• 弱分类器选择: CART决策树
• 随机性: 在生成每棵树的时候,每个树选取的特征都仅仅是随机选出的少数特征,一般默认取特征总数m的开方。而一般的CART树则是会选取全部的特征进行建模。因此,不但特征是随机的,也保证了特征随机性。
• 样本量:相对于一般的Bagging算法,RF会选择采集和训练集样本数N一样个数的样本。
• 特点:由于随机性,对于降低模型的方差很有作用,故随机森林一般不需要额外做剪枝,即可以取得较好的泛化能力和抗过拟合能力(Low Variance)。当然对于训练集的拟合程度就会差一些,也就是模型的偏倚会大一些(High Bias),仅仅是相对的。
梯度迭代决策树(Gradient Boosting Decision Tree)
简介:
GBDT树也是一种集成模型,GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。它在被提出之初就和SVM一起被认为是泛化能力较强的算法。GBDT中的树是回归树(不是分类树),GBDT用来做回归预测,调整后也可以用于分类。GBDT的思想使其具有天然优势可以发现多种有区分性的特征以及特征组合。业界中,Facebook使用其来自动发现有效的特征、特征组合,来作为LR模型中的特征,以提高 CTR预估(Click-Through Rate Prediction)的准确性;GBDT在淘宝的搜索及预测业务上也发挥了重要作用。
GBDT树特点:
• 精度高
• 可处理非线性数据
• 处理多特征类型数据
• 适合低维稠密的数据
• 不需要做特征的归一化,可以自动选择特征
• 能适应多种损失函数
• 计算复杂度大
• 不适用高维度稀疏特征特征
实验流程
实验环境
实验数据:
来自天池大数据竞赛平台的天池离线赛-移动推荐算法(https://tianchi.aliyun.com/competition/entrance/231522/information)
实验环境:
使用软件:
• jupyter notebook 利用python中的pandas和numpy进行数据预处理,特征提取,提取训练集等操作
• 阿里PAI 机器学习平台 进行模型训练
• Excel 进行数据可视化
实验要求:
使用训练数据建立推荐模型,并输出用户在接下来一天对商品子集购买行为的预测结果。即预测12.19这一天用户在P上的购买情况。
源数据展示
源数据分为两个csv文件,一个数据集为用户行为数据userdataori,另一个数据集为商品数据itemdataori.
用户行为数据字段(如图1a),他包含一个月内所有的用户的行为数据,每一个数据项为某个用户对于某个商品的行为
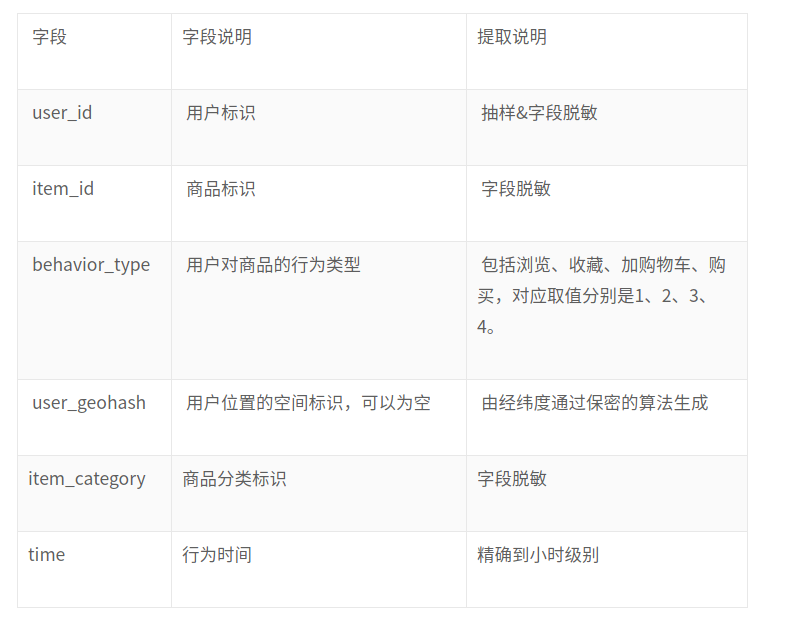
图1a
用pandas读入数据后整个数据集的信息(如图1b)整个数据集有2300万条数据项,内存占用1G+.
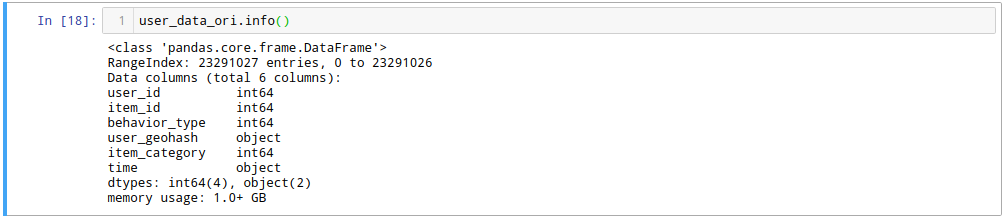
图1b
物品行为数据字段(如图2a),它包含要求推荐物品的信息.
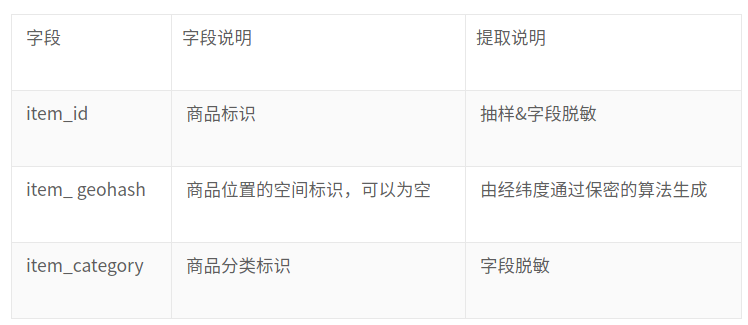
图2a
用pandas读入数据后整个数据集的信息(如图2b)整个数据集有60w条数据项内存占用14.2MB

数据预处理
对于userdataori这样耗费内存上1G的数据,硬件设施不足以支持我们直接对其进行处理.所以要对其进行初步的筛选.因为数据文件太大,不好操作进行可视化,因此直接统计进行判断
缩小item域
根据要求推荐的物品必须是在itemuserori里面出现的物品,但是通过统计userdataori里面的Item数远大于itemuserori里面的Item数(如图3b),因此我们对于进行了一次筛选,将所有itemid**不在itemdata_ori域内的行为数据项进行筛除

图3b
分层抽样
查看userdataori中行为类型的分布(如图3a),发现浏览次数远大于其他三种类型的行为次数,显然这也是符合生活常识的,主观上认为,在这些浏览次数中有部分是属于无效浏览.采用了分层抽样,对于加购物车,收藏和购买行为进行100%抽样,对于浏览行为进行0.5的随机抽样.

图3a
通过对上面两次筛选之后的数据集的信息(如图3c),总数据项数有110w条,内存占用大小50MB,此操作后的数据在后文中将作为主要数据源称其为user_data
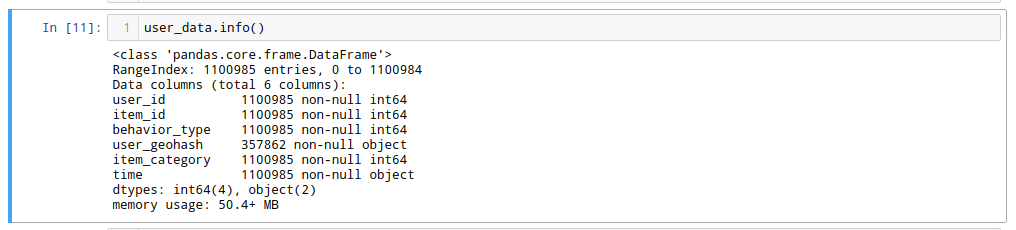
图3c
数据可视化
精准到天对行为总数进行统计
将user_data数据源按照天数进行分类,统计每天的行为总数(图4a),可以看到每天的行为成相对稳定的状态,除了双十二(因为促销活动,所以行为异常火爆)有较为异常的行为数量波动,根据图4a可知,在进行提取数据时,应讲双十二周围的数据剥离,对于平常的一天来说,若以双十二的数据为训练样本,训练结果显然会产生偏差.
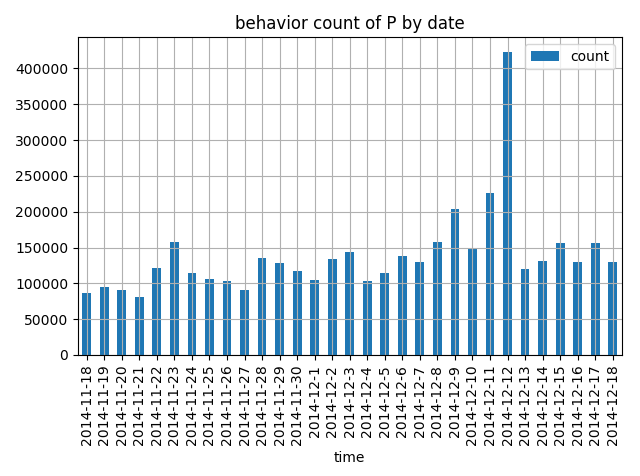
图4a
精准到小时对加购物车行为进行统计
将17-18号两天的behavior数据精确到小时之后进行统计可视化(图4b),可以看到加购物车行为一般发生在白天,凌晨加购物车行为较少.
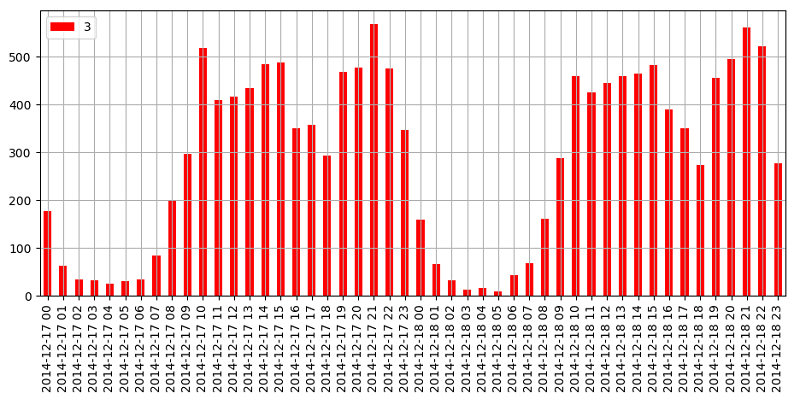
图4b
对于每天购买行为在前1,3,6天是否发生发生过交互的统计即可视化
这是一个十分重要的可视化,直接对后面的建模方式和特征提取产生了影响,
• 对于18号的所有购买行为,在之前一个月中对于每一条购买行为,之前有过交互的购买行为占所有购买行为的比例(图5a) 其中橙色代表没有交互的购买行为占比,蓝色代表有交互的购买行为占比.
• 精准到天对于每一天的购买行为统计在这些确定曾经发生过交互的购买行为中有哪些在前1,3,6天是否会发生过交互(图5b),其中蓝色,橙色,灰色分别代表前一,三,六天有交互的购买行为统计,
• 平均每天的信息之后,前一天发生交互后的购买行为数,前3天发生交互后的购买行为数-前1天发生交互后的购买行为数,前6天发生交互后的购买行为数-前3天发生交互后的购买行为数.做饼图(图5c)
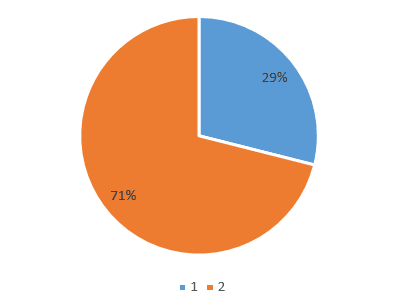
图5a
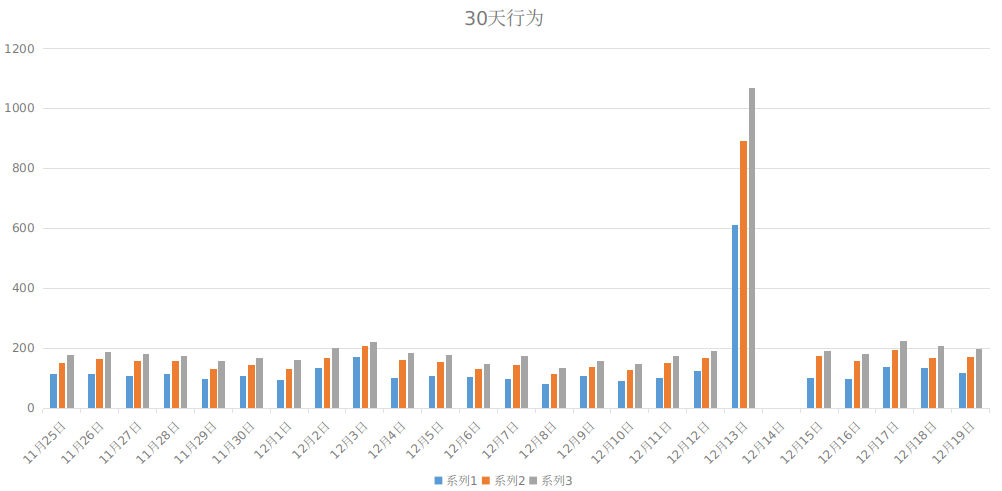
图5b
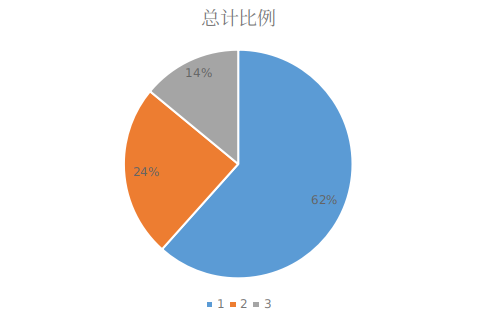
图5c
三个图分别解释了三个现象:
• 图5a对于每一天的购买行为来说,其中71%的购买行为,用户和商品在之前没有交互,29%的购买行为,用户和上坪在之前有交互.
• 图5c对于有交互的购买行为来说,其交互的行为大部分出现在前1天内
• 图5b解释了上一条结论在每一天的表现都是稳定,可以近似看做每一天都是等价的
建模方案选择
排除传统推荐算法
对于商品推荐来说传统的推荐算法已经相对成熟,可以利用协同过滤算法,基于内容的推荐算法,基于用户的推荐算法等等.这些算法都有一个共通点,当数据量庞大的情况下,构造的无论是用户-物品矩阵还是物品-物品矩阵都十分的庞大,对于该数据集用户-物品矩阵是一个2w*60w的矩阵,物品-物品矩阵是一个60w×60w的矩阵,初始化矩阵后,又有110w条数据项要对矩阵进行操作.无论是内存还是cpu在现有实验条件下都是不支持的.因此利用传统推荐算法是行不通的.
采用机器学习算法
我们分析实验要求,最后要求的结果是19日的给用户-推荐商品的元组,我们将这个问题进行分析,其实就是判断某个用户是否购买一些商品.(图6a)为逻辑上的伪代码,其中确定了推荐当天的用户域和物品域(在本试验中默认User和Item为全部用户域和全部物品域),最后只要确定如何去判断用户是否购买当前物品即可.那么接下来就是如何去构建这个模型去判断是否购买.这样一个推荐算法就被简化成了一个二分类问题
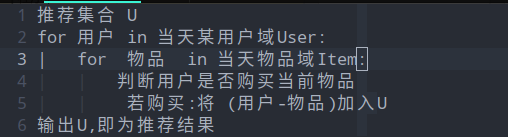
特征提取
对于该数据集,特征提取是一个难点,因为在源数据集中几乎没有任何一个字段可以直接作为该模型的特征,再次分析得出下面一个公式:
什么样的用户+什么样的商品+该用户和该商品之前进行什么样交互=购买
这些”什么”就是要提取的特征,根据上面的公式,可以得出这样几个域(图7a),首先我们要构建图7a中的三种数据库
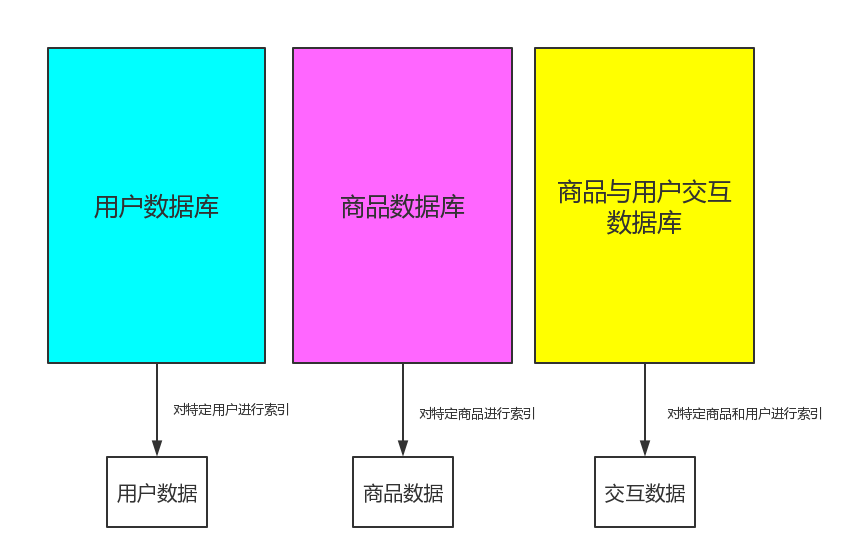
根据图5c做的数据可视化发现在判断当天的购买行为时,我们取前一个月的交互信息,和取前1天或前几天的的交互信息相比,虽然一个月的交互信息要更全,但是却有更多的噪声,可能作为特征,取前几天的交互信息会效果更好.而且主观上进行分析,当大部分普通人买一个普通物品时,可能并不需要1个月的考虑,可能就是在2,3天时间考虑后就进行了购买.因此在构建这些数据库时我们对数据的时间区间进行了分割.
同时主观上来说,对于购买行为来说,用户的权重应该比商品大,所以在特征提取过程中,倾向于多提取用户的特征,以及用户交互的特征.
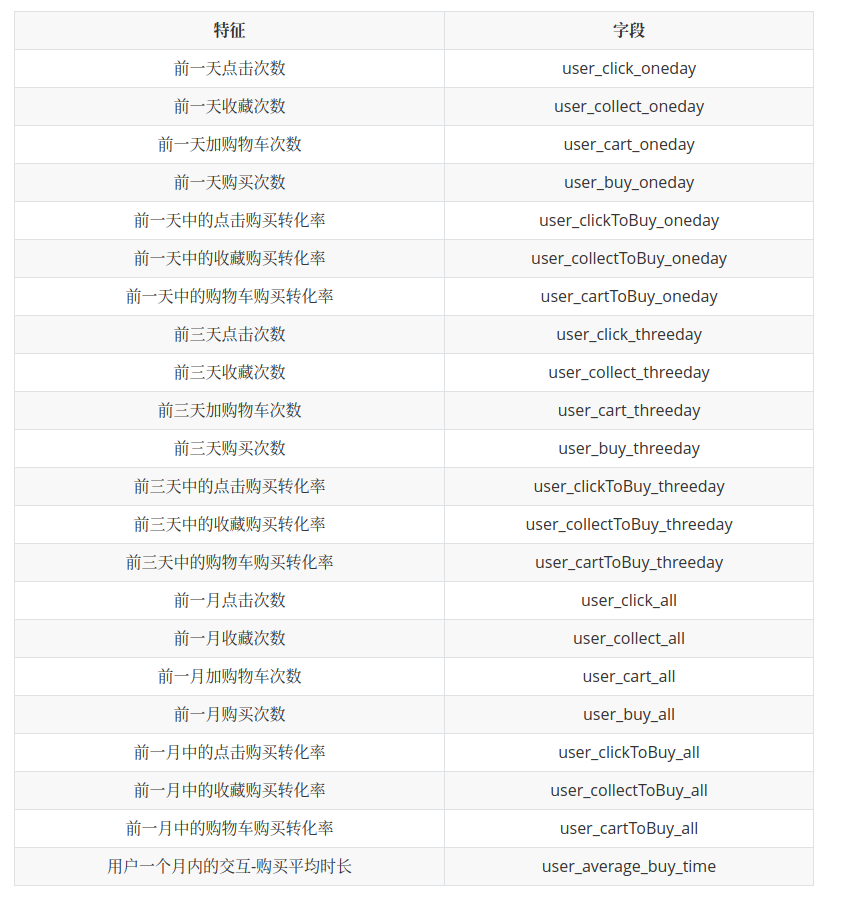
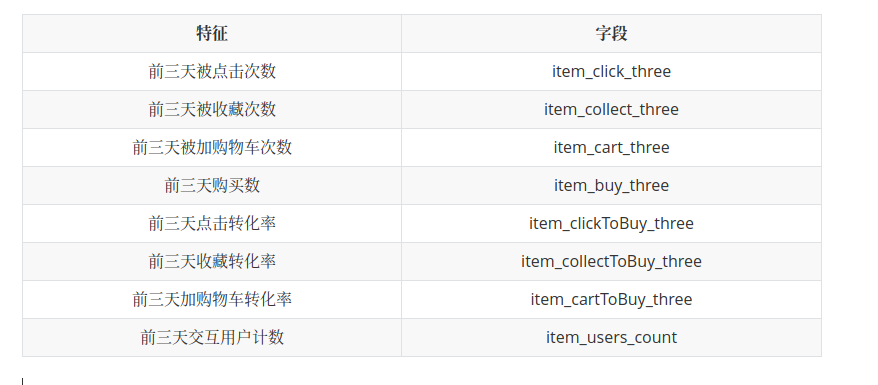
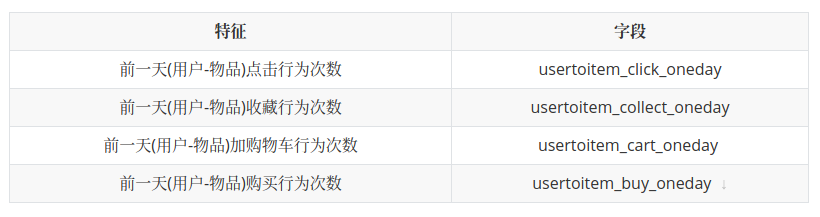
最后用户数据库的构成是用户1个月内的数据统计,用户三天内的行为数据统计,用户一天内的行为数据统计.商品数据库为商品三天内的行为数据统计,商品与用户交互数据库为1天内的交互行为的统计.我们最终提取了下列34个特征.
用户域特征
商品域特征
交互行为特征域
构造训练样本
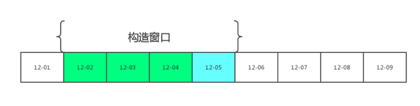
在构造样本过程中,显然正负样本是极不均衡的,对于某一天来说正样本数量是远小于负样本数量的,所以我们利用了一个滑动窗口的方法,根据图5b可视化结果可知,我们所要提取的规则对于每一天都存在,因此每一天的数据价值相等,逻辑上我们设置一个窗口进行构造样本数据(图8a),蓝色日期离提取购买行为,根据购买行为在绿色窗口里构造训练样本
构造正样本
如何取构造正样本(图8b)
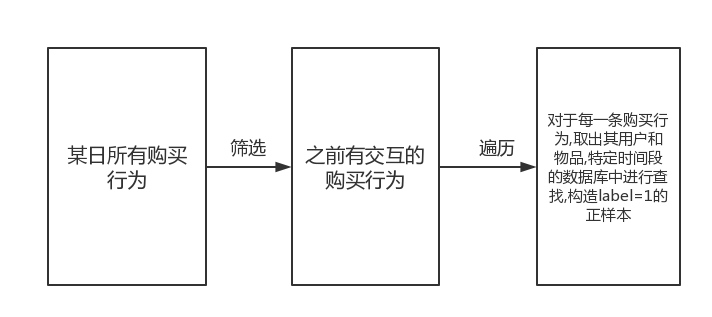
图8b
构造负样本
因为负样本没有明显的提取负样本的域,我们要自定义一个域,同时为了保持正负样本平衡,在构造时应该根据正样本的个数进行构造,如下进行负样本提取(图8c)
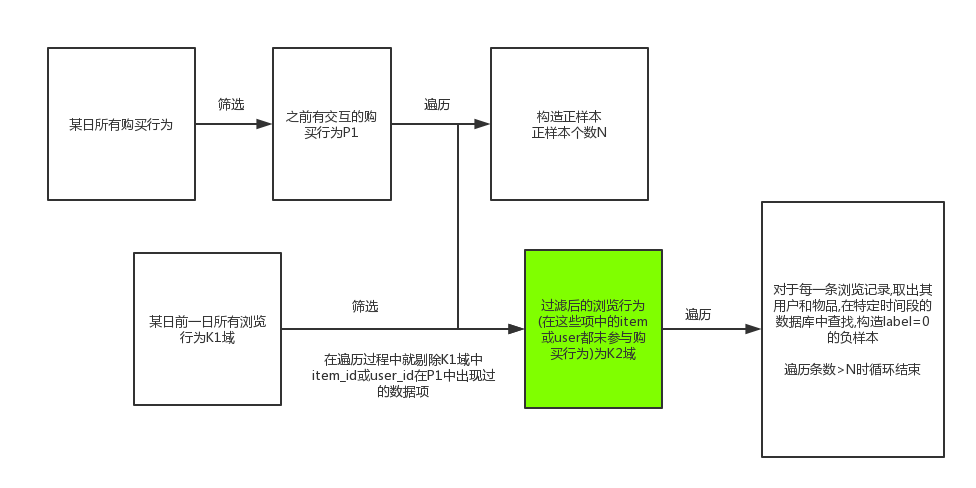
图8c
训练集参数
图8d中,提取出来的有效的训练集1.3w条,内存占用3.6MB,其中正样本:负样本=1:1
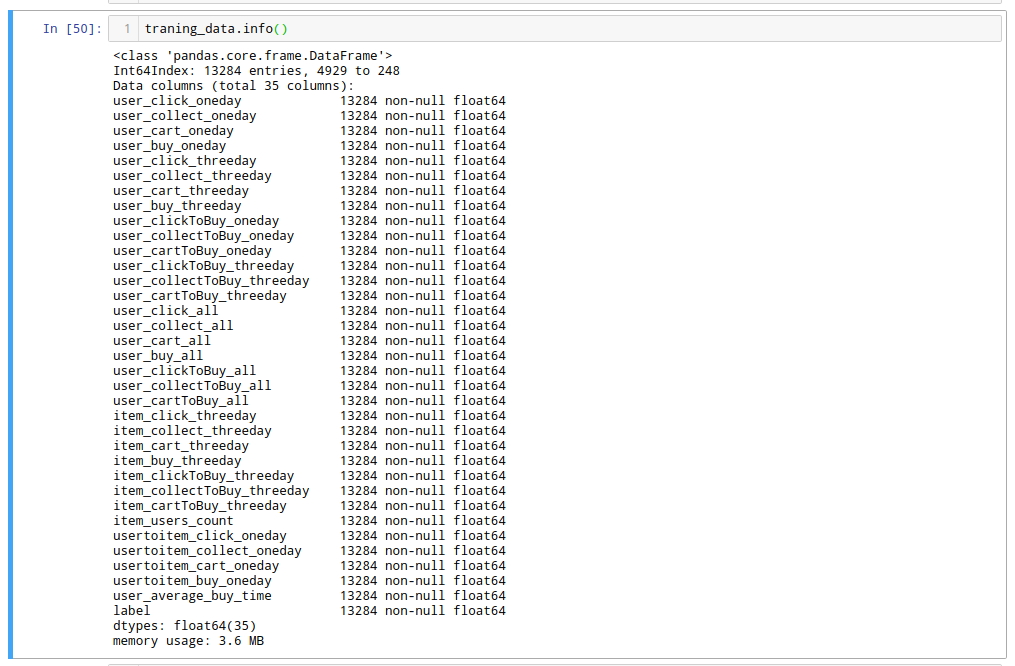
模型训练
在青苔大数据平台上进行训练过程如图9a,运用了四种分类算法进行训练
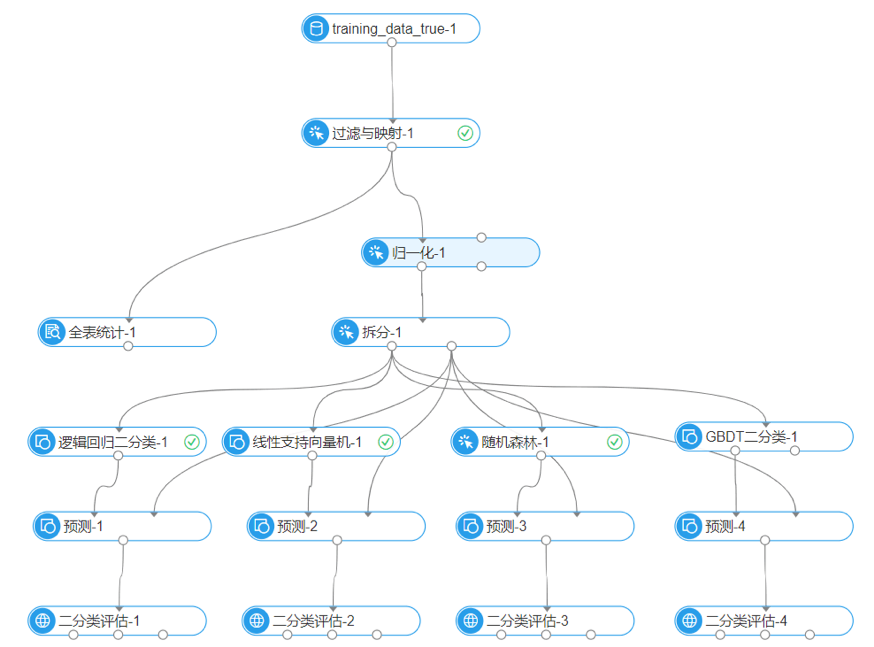
逻辑回归预测结果如图9b,SVM(线性核)预测结果如图9c,RF预测结果如图9d,GBDT预测结果如图9e
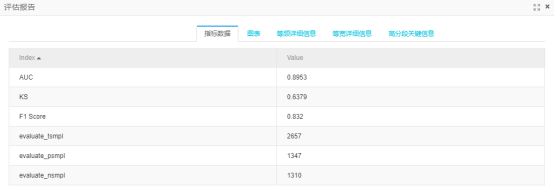
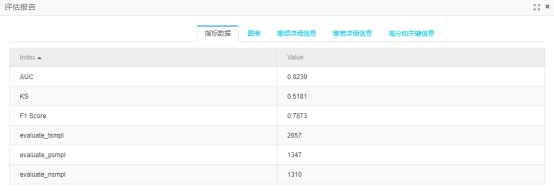
图9c
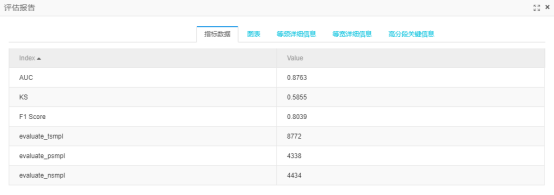
图9d
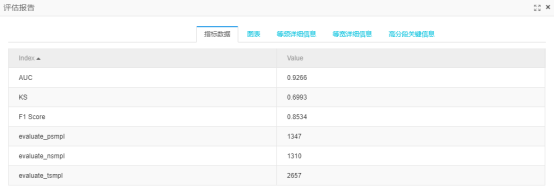
所有结果比较:
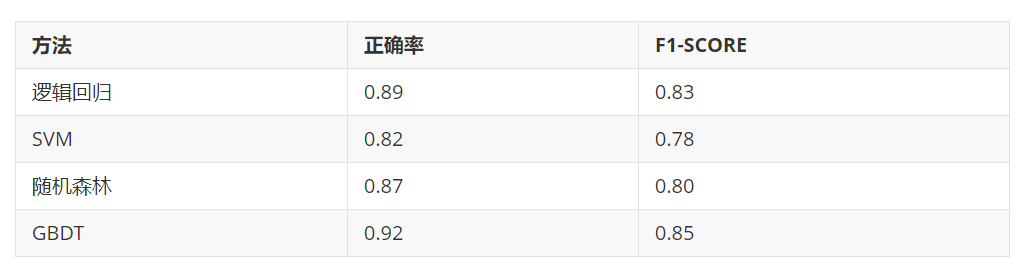
最后选择两项都效果最好的GBDT树模型
实验总结
在整个试验流程中,特征提取这一块是非常重要的,如何取提取特征,基础特征组合形成高阶特征,特征的好坏直接决定了模型最后的效果,比较了之前的优秀的特征工程,我们的特征工程还是较为基础,只提取了34特征,而且特征之间组合只是基础的转化率,还丢掉了数据中的类,地点,精准到小时的特征.这也是模型未取得较好效果的原因.