Mac OS上 Hadoop 2.7.3 安装与使用
author: Zreal
平台:MAC OS
安装Hadoop
Hadoop 分为 单机版本(local mode) 伪分布式版本(Peseudo-Distributed mode)和完全分布式版本(Fully Distributed mode)
下文中介绍单机版本和伪分布式版本配置
前期条件 Prerequisites
- JAVA 必须先行安装
- ssh必须先行安装
单机版本配置(Local Mode)
Mac OS 可以用homebrew 直接 brew install hadoop 下载,但下载的是最新版本。所以下文手动下载
Step 1
下载hadoop 2.7.3 压缩包,解压到当地文件夹
Step 2
配置环境变量
修改配置文件.zshrc或.bash_profile文件
加入如下配置
1
2
export HADOOP_HOME="/Users/e1ixir/hadoop-2.7.3"
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
其中HADOOP_HOME为解压之后的文件夹
之后在命令行中键入hadoop version如下结果:

配置配置文件
配置文件{HADOOP_HOME}/etc/hadoop/hadoop-env.sh加入下列配置
1
2
export JAVA_HOME={LOCAL_JAVA_HOME}
export HADOOP_PREFIX={LOCAL_HADOOP_HOME}
注LOCAL_JAVA_HOME为本地java路径
#在命令行中键入
/usr/libexec/java_home可以得到JAVA命令LOCAL_HADOOP_HOME为本地hadoop作赛文件夹
伪分布式配置(Peseudo-Distributed Mode)
在单机配置的基础上继续修改相应配置文件
该步骤中未启用yarn 框架
step1:修改配置文件
进入文件{HADOOP_HOME}/etc/hadoop/core-site.xml添加
1
2
3
4
5
6
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
进入文件{HADOOP_HOME}/etc/hadoop/hdfs-site.xml添加
1
2
3
4
5
6
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Step2:设置无需密码ssh
键入 ssh localhost看是否需要密码,如果需要跳过本步骤
如果不能无密码登陆ssh,键入
1
2
3
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
Step3:初始化NameNode,打开hdfs
键入
1
$ hdfs namenode -format
(注:这里我配置了环境变量,如果为配置,应到{HADOOP_HOME}/bin目录下执行此次命令)

成功
键入
1
$ start-dfs.sh
(若未配置环境变量,应到{HADOOP_HOME}/sbin目录下执行此次命令)
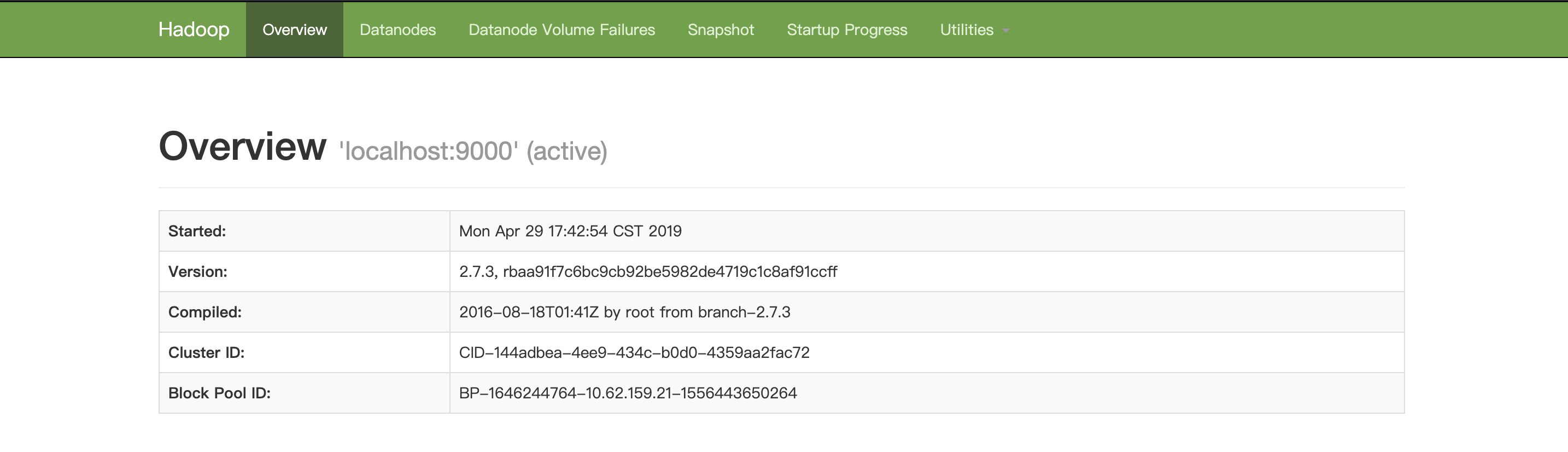
Step4:检查是否配置成功
浏览器打开:点一下兄弟
出现如下页面:
键入
1
$ jps

键入
1
$ hadoop fs -ls /
可以看到 根目录下的文件

Hadoop 自带用例测试
进入文件夹{HADOOP_HOME}/share/hadoop/mapreduce,该目录下有文件hadoop-mapreduce-examples-2.7.3.jar,该文件为测试代码的jar包。
(可以将其移动到测试文件下,也可以不移动,本文将其拷贝到了测试文件夹下)
键入
1
$ hadoop jar hadoop-mapreduce-examples-2.7.3.jar
(注:这是一条无效指令)
但是你可以看到:
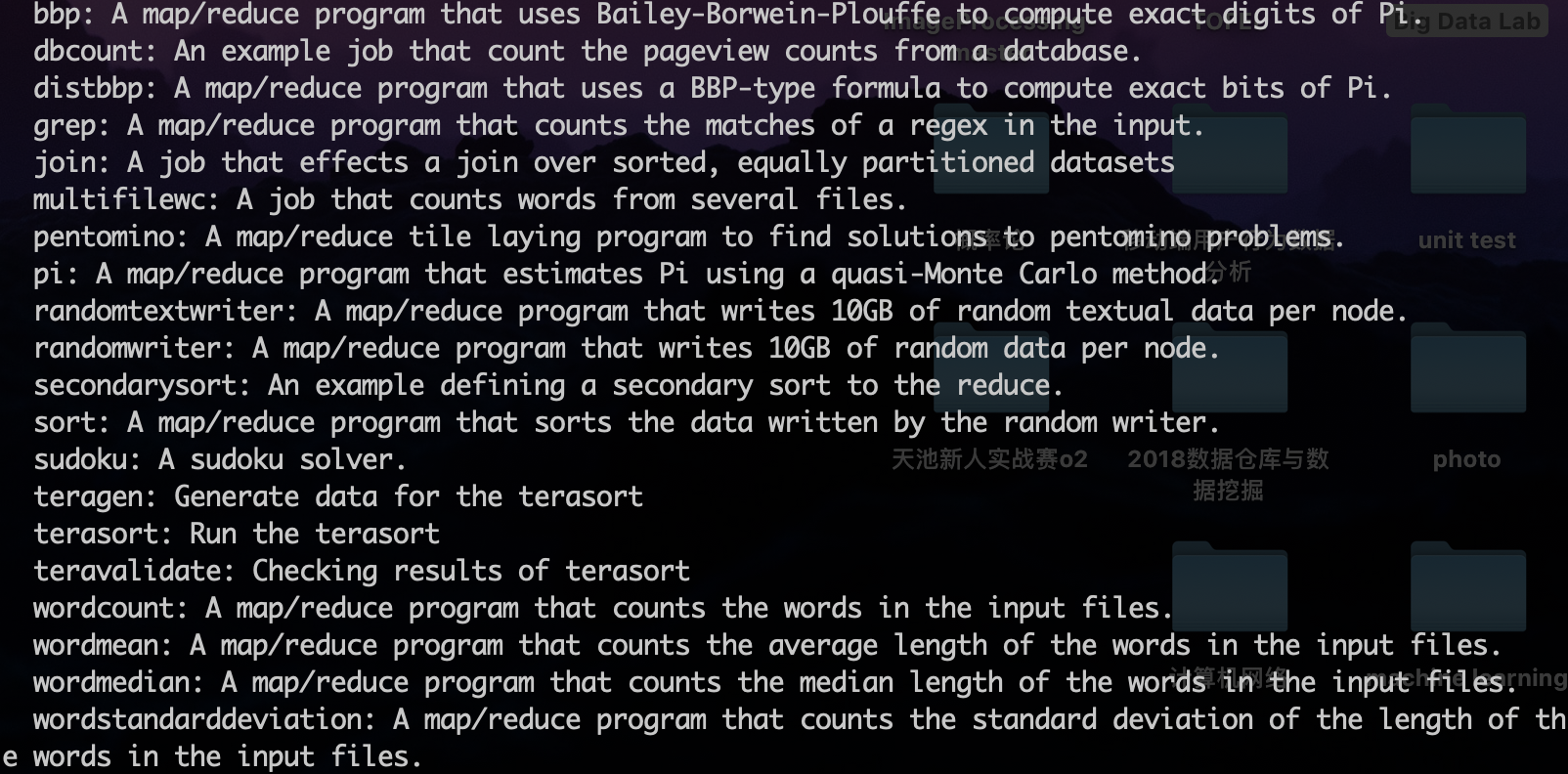
挑选一个自己喜欢的例子进行测试吧,(下文中测试了wordcount和wordmean)
单机版Hadoop测试
单机版一定要将伪分布式版本的配置文件清楚,否则无法运行
WordCount 测试
统计词频
新建 wc_input 文件夹,其中新建文件 file1.txt
1
2
3
$ mkdir wc_input
$ cd wc_input
$ vim file1.txt
输入:

终端运行命令:
1
$ hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount ./wc_input ./wc_output
(注,wc_output文件应为还未存在的文件夹,若执行成功,会打印执行结果,实验过久截图丢失,就不贴图了,过程图片在后面伪分布式部分展示)
输入
1
2
$ cd wc_output
$ cat part-r-00000
如下结果

WordMean测试
统计平均词长
整个操作流程和上个样例相似
新建 wa_input 文件夹,其中新建文件 file1.txt
1
2
3
$ mkdir wa_input
$ cd wa_input
$ vim file1.txt
输入:
终端运行命令:
1
$ hadoop jar hadoop-mapreduce-examples-2.7.3.jar mean ./wa_input ./wa_output
(注:wa_output文件应为还未存在的文件夹,若执行成功,会打印执行结果,实验过久截图丢失,就不贴图了,过程图片在后面伪分布式部分展示)
输入
1
2
$ cd wa_output
$ cat part-r-00000
如下结果

伪分布式版测试
大致流程和单机版相似,其中添加一步将文件上传到hdfs上
WordCount Test
hdfs上新建文件夹
1
$ hadoop fs -mkdir -p /test/wc_input
传文件到wc_input
1
$ hadoop fs -put file1.txt /test/wc_input
运行应用
1
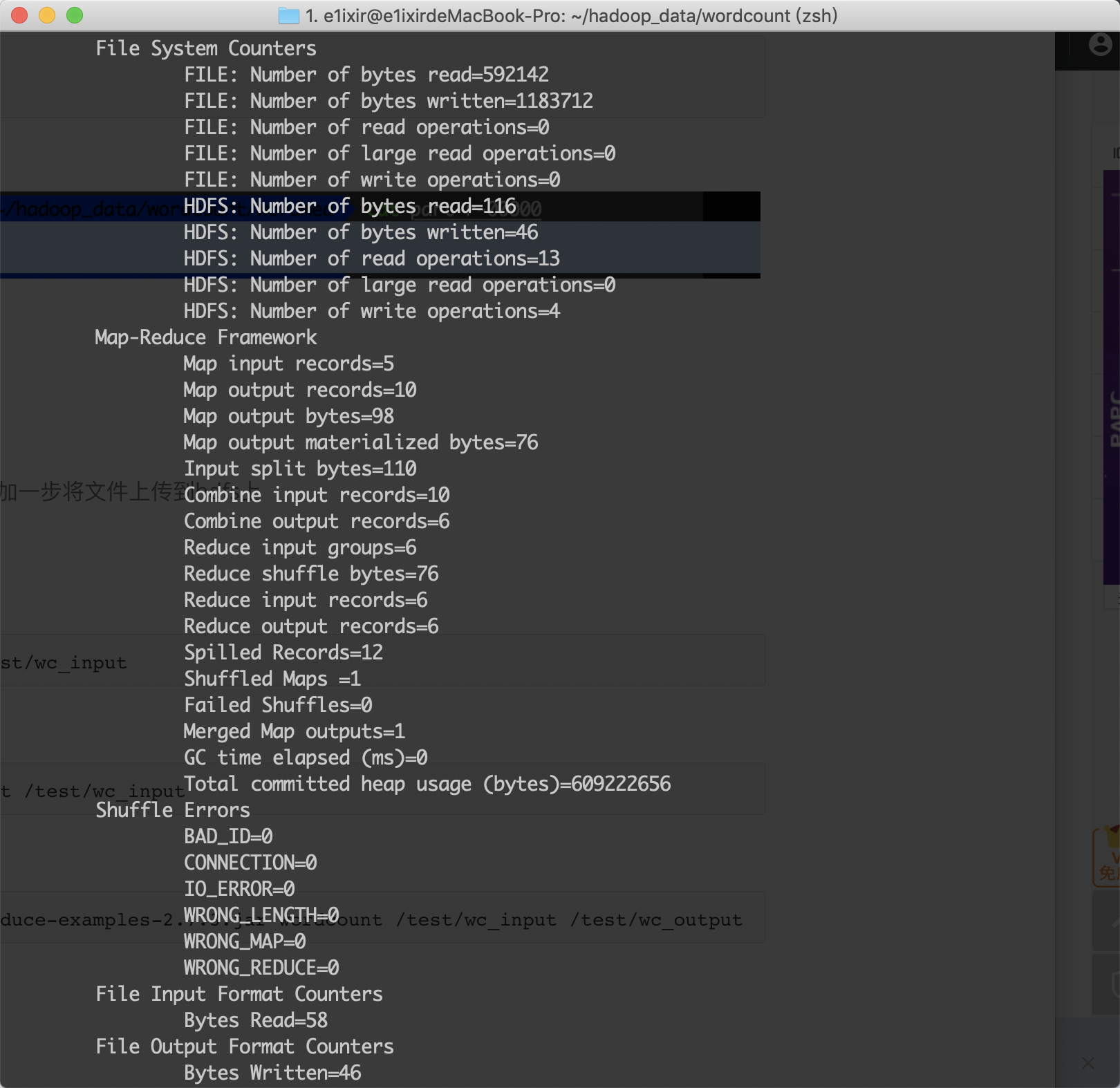
$ hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /test/wc_input /test/wc_output
出现如下结果:
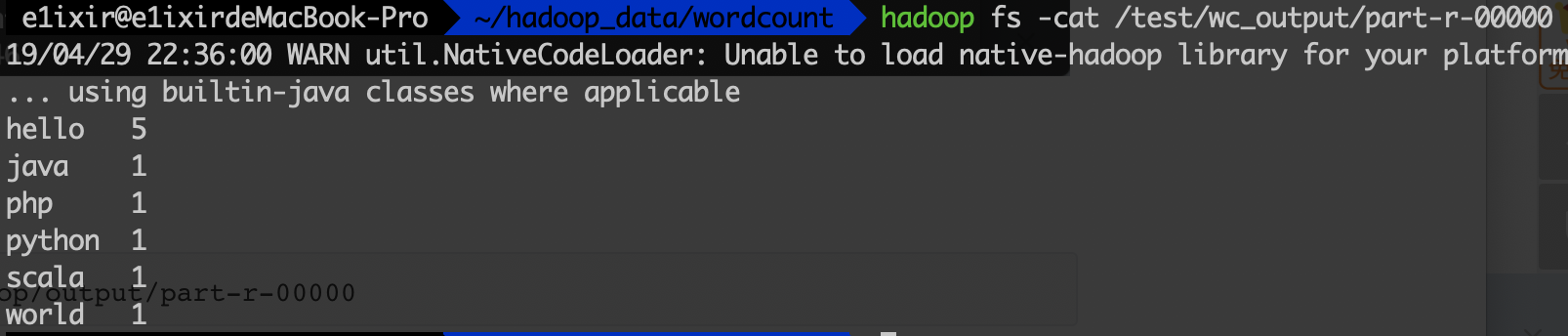
查看结果:
1
hadoop fs -cat /test/wc_onput/part-r-00000
WordMean Test
hdfs上新建文件夹
1
$ hadoop fs -mkdir -p /test/wa_input
传文件到wc_input
1
$ hadoop fs -put file1.txt /test/wa_input
运行应用
1
$ hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /test/wa_input /test/wa_output
出现如下结果:

查看结果:
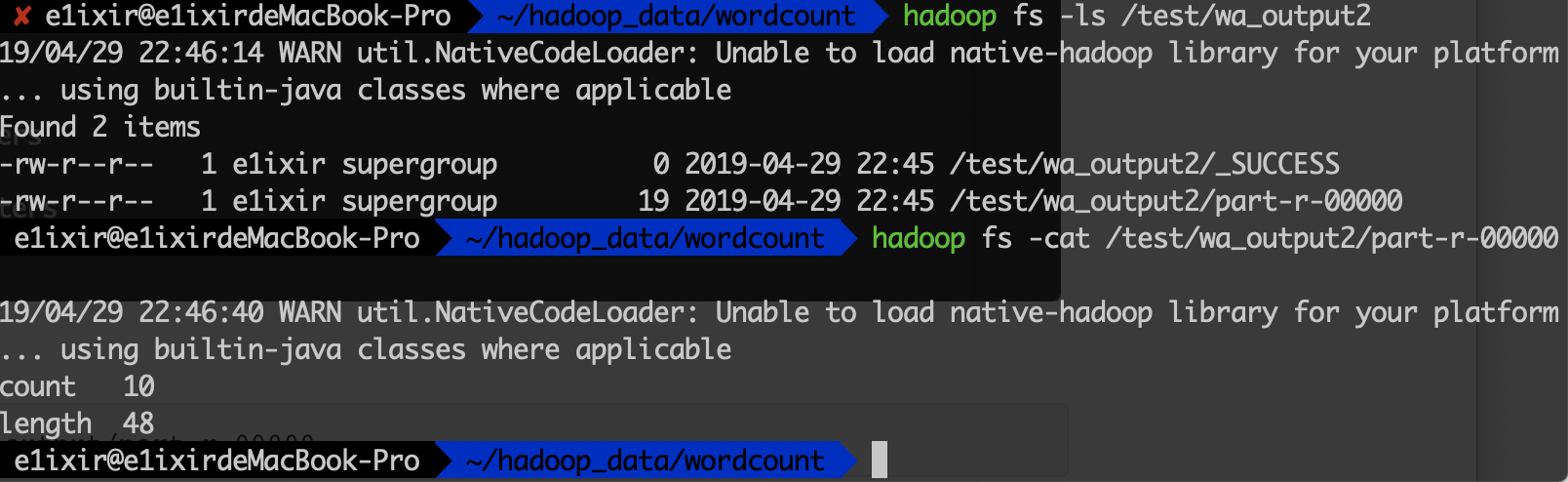
1
$ hadoop fs -cat /test/wa_output/part-r-00000
待改进方面及相关参考
Warning: Native Library
 解决方法:本地编译hadoop源码,还未尝试
解决方法:本地编译hadoop源码,还未尝试
参考:(需VPN)
- https://medium.com/@faizanahemad/hadoop-native-libraries-installation-on-mac-osx-d8338a6923db
- https://stackoverflow.com/questions/37800605/hadoop-native-libraries-not-found-on-os-x
Error: Connection Refused
解决方法:MAC OS系统设置
参考:https://zhuanlan.zhihu.com/p/33117305
Others
- https://www.jianshu.com/p/de7eb61c983a
- https://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/SingleCluster.html