linux系统下ext文件系统详解
参考博客:https://www.cnblogs.com/f-ck-need-u/p/7016077.html
博主写的很好,本人只是在内容下面加上了一些自己的理解
ext文件系统的组成部分
block (块)
硬盘读写IO一次是一个扇区512字节,如果要读写大量文件,以扇区为单位肯定很慢而且消耗性能。所以Linux中通过文件件系统控制使用’块’为读写单元。块的大小一般为1K,2K,4K。比如需要读一个或多个块时,文件系统的IO管理器通知磁盘控制器要读取哪些块数据,硬盘控制器将这些块按扇区读写出来。可以块看做文件系统读写的最小单位
Block的出现使得在文件系统层面上读写性能大大提高,也大量减少了碎片(每次读写的最小单位都是多个扇区)。但是它的副作用是造成空间浪费,英文文件系统已block为读写单元,纪实储存的文件只有1K大小也将会占用一个block,剩余的空间完全浪费。在某些业务情景下,大量储存小文件可能会造成大量的浪费。
inode (索引节点)
如果一个文件占用了大量的block读取时会如何?想想操作系统课上有三种读取文件的方式:
-
连续访问
-
链接访问
-
索引访问
这里ext文件系统运用了索引访问的方式,其中inode就类似于那个索引访问的索引表,inode中不仅包含索引,而且包含部分文件的信息,例如每个文件都有属性(如权限,大小,时间戳等)这些属性都存储在inode之中。一般来说索引节点(inode)占用的空间相比其索引的文件数据而言占用的空间小很多,扫描它比扫描整个数据要快很多。这样一来就解决了上面的问题,读取inode就可以找到属于该文件的block,进而读取这些block并获得该文件的数据。
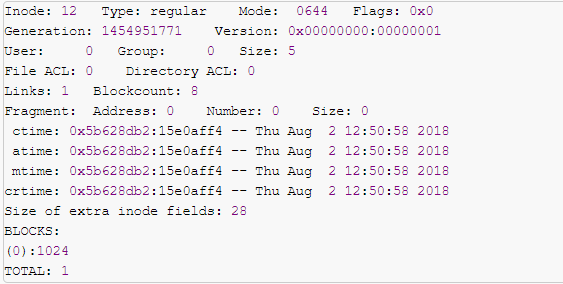
下图为linux下ext2文件系统的inode信息示例
bmap(块位图)
在向硬盘存储数据时,文件系统需要知道那些块时空闲的额,那些快已经被占用了,可以全局扫描,遇到空闲块就存储一部分,继续扫描直到存储完所有数据。
因为对于每一个block 我们只需要直到其是否被占用,及用一个bool就可表示一个块的占用情况。一个更高阶的优化方法:块位图bitmap,我们用一个bit来标识一个对应的块是否被占有。
考虑下为什么块位图更优化。在位图中1个字节8个位,可以标识8个block。对于一个block大小为1KB、容量为1G的文件系统而言,block数量有1024×1024个,所以在位图中使用1024×1024个位共1024*1024/8=131072字节=128K,即1G的文件只需要128个block做位图就能完成一一对应。通过扫描这100多个block就能知道哪些block是空闲的,速度提高了非常多。
但是要注意,bmap的优化针对的是写优化,因为只有写才需要找到空闲block并分配空闲block。对于读而言,只要通过inode找到了block的位置。
inode table(inode表)
在当前文件系统中inode存储了inode号、文件属性元数据、指向文件占用的block的指针;每一个inode占用128字节或256字节。一个文件系统中可以说有无数多个文件,每一个文件都对应一个inode,难道每一个仅128字节的inode都要单独占用一个block进行存储吗?这太浪费空间了。
所以更优的方法是将多个inode合并存储在block中,对于128字节的inode,一个block存储8个inode,对于256字节的inode,一个block存储4个inode。这就使得每个存储inode的块都不浪费。
在ext文件系统上,将这些物理上存储inode的block组合起来,在逻辑上形成一张inode表(inode table)来记录所有的inode。
注意:这里我们会发现inode也是存储在block之中的,block是一个物理上的概念,它是文件系统IO读写的最小单位,而inode,data block(这里叫data block 区别block)是逻辑上的概念
实际上,在文件系统创建完成后所有的inode号都已经分配好并记录到inode table中了,只不过被使用的inode号所在的行还有文件属性的元数据信息和block位置信息,而未被使用的inode号只有一个inode号而已而没有其他信息而已。
imap (inode位图)
其结构与bmap相同,用于标识哪些inode block是空闲的哪些block是占用的。
块组
现在有这样一个问题:如果文件系统比较大,imap和bmap本身就比较大。如果文件系统是100G,100G的文件系统要使用128*100=12800个1KB大小的block,这就占用了12.5M的空间了。虽然12.5M相比100G并不大。但是对于bmap来说这一块要求的是一块连续的内存。虽然扫描迅速,但是每一次存储文件都要扫描会带来巨大的开销。
优化的方法:在物理层面上:将磁盘按柱面划分为多个分区,即多个文件系统;在逻辑层面上的划分是将文件系统划分成块组。每个文件系统包含多个块组,每个块组包含多个元数据区和数据区:元数据区就是存储bmap、inode table、imap等的数据;数据区就是存储文件数据的区域。注意块组是逻辑层面的概念,所以并不会真的在磁盘上按柱面、按扇区、按磁道等概念进行划分。
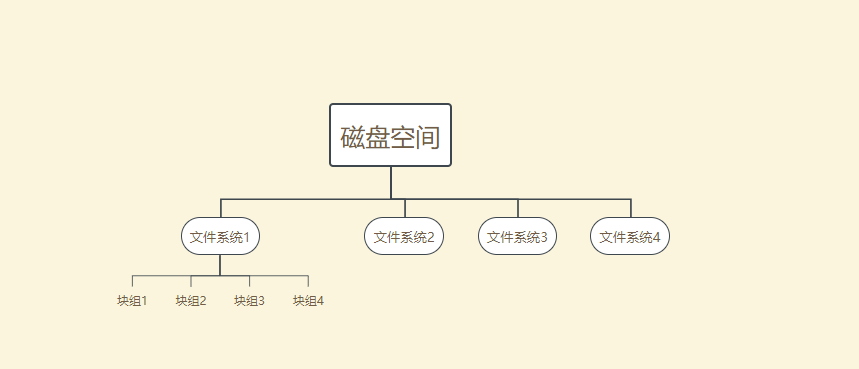
块组的划分
块组在文件系统创建完成后就已经划分完成了,也就是说元数据区bmap,inode,table和imap等信息已经划分好了
如何确定这些数据大小:
它只需确定一个数据——每个block的大小,再根据bmap至多只能占用一个完整的block的标准就能计算出块组如何划分。
例子:
假如现在block的大小是1KB,一个bmap完整占用一个block能标识1024*8= 8192个block(当然这8192个block是数据区和元数据区共8192个,因为元数据区分配的block也需要通过bmap来标识)。每个block是1K,每个块组是8192K即8M,创建1G的文件系统需要划分1024/8=128个块组,如果是1.1G的文件系统呢?128+12.8=128+13=141个块组。
每个组的block数目是划分好了,但是每个组设定多少个inode号呢?inode table占用多少block呢?这需要由系统决定了,因为描述”每多少个数据区的block就为其分配一个inode号”的指标默认是我们不知道的,当然创建文件系统时也可以人为指定这个指标或者百分比例。
下图是一个文件系统的部分信息,在这些信息的后面还有每个块组的信息,其实这里面的很多信息都可以通过几个比较基本的元数据推导出来。

文件系统完整的结构
对于每个文件系统:

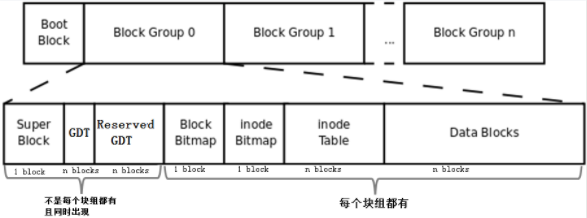
super block (超级块)
super block里面装着文件系统的格式信息,例如:个块组又有多少block多少inode号等等信息呢?还有,文件系统本身的属性信息如各种时间戳、block总数量和空闲数量、inode总数量和空闲数量、当前文件系统是否正常、什么时候需要自检等等。
super block 占用一个block结构。使用df命令读取每个文件系统的super block 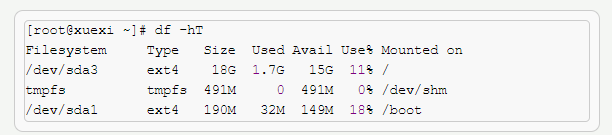
可以看到里面记录了每个文件系统的类型,大小,可用空间,已用空间。
superblock对于文件系统而言是至关重要的,超级块丢失或损坏必将导致文件系统的损坏。所以旧式的文件系统将超级块备份到每一个块组中,但是这又有所空间浪费,所以ext2文件系统只在块组0、1和3、5、7幂次方的块组中保存超级块的信息,如Group9、Group25等。尽管保存了这么多的superblock,但是文件系统只使用第一个块组即Group0中超级块信息来获取文件系统属性,只有当Group0上的superblock损坏或丢失才会找下一个备份超级块复制到Group0中来恢复文件系统。
GDT 块组描述符表
super block是用来记录整个文件系统的格式信息,那么对于每一个块组的信息,它保存在哪里。
ext文件系统的每一个块组信息使用32字节描述,这32字节成为块组描述符,所有的块组描述符表组成块组描述符表GDT。
可想而知对于每一个文件系统他的GDT应该是相同的,GDT与超级块的存储与备份一样,他们同时出现在一个块组中,读取时也总是块组0中的块组描述符表的信息。
Reserved GDT(保留GDT)
保留GDT用于扩容文件系统使用,防止扩容后块组太多。
Data Block(数据块)
数据所占用的block由文件对应inode记录中的block指针找到,不同文件类型,数据block中储存的内容不同,在Linux不同类型文件的储存方式中:
- 对于常规文件,文件数据正常储存在数据块中。
- 对于目录,该目录下的所有文件和以及子目录的目录名储存在数据块中(文件名储存在data block中,不储存在inode中)
- 对于符号链接,如果路径名较短直接保存在inode中以便更快的查找,如果路径名较长则分配一个数据快来保存
- 设备文件,FIFO和socket等特殊文件没有数据块,设备文件的主设备号和此设备号保存在inode中。
目录文件的data block
目录文件的inode中储存:目录的inode号,目录的属性元数据和目录文件的block指针,(没有储存目录名)
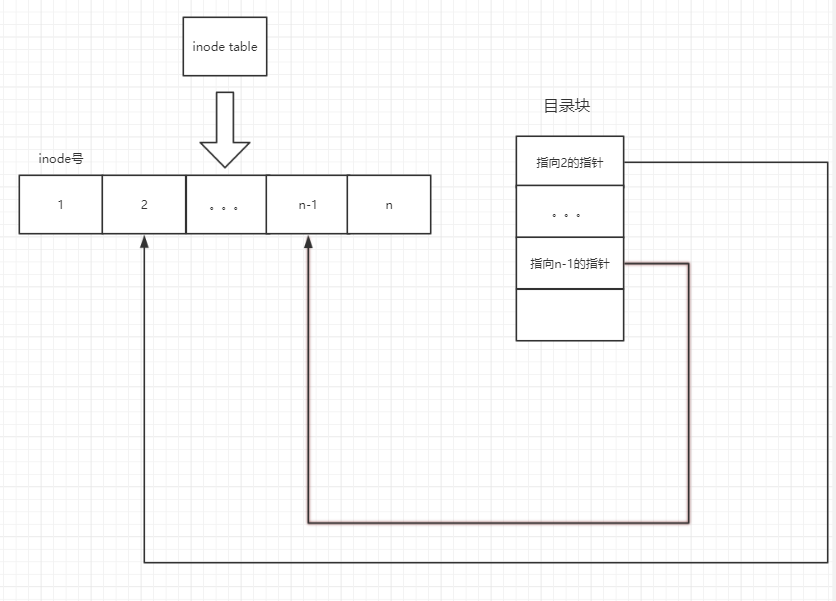
目录文件的数据块中储存了:其下的文件名,目录名,目录本身的相对路径’.’,上级目录的路径’..’。还储存了指向inode table中这些文件对应的inode号的指针,目录项长度rec_len,文件名长度name_len和文件类型file_type。
目录的数据块中储存的不是目录中文件的inode号,而是指向inode table中对应文件inode号的指针
如图显示:
inode详解
硬连接
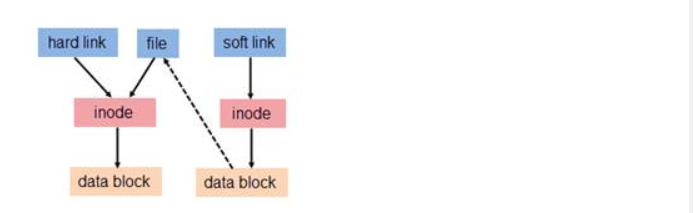
定义:虽然每个文件都有一个inode,但是存在一种可能:多个文件的inode相同,也就即inode号、元数据、block位置都相同,这是一种什么样的情况呢?能够想象这些inode相同的文件使用的都是同一条inode记录,所以代表的都是同一个文件,这些文件所在目录的data block中的inode指针目的地都是一样的,只不过各指针对应的文件名互不相同而已。这种inode相同的文件在Linux中被称为”硬链接”。
换而言之硬链接是同一个文件存在多个别名,由于硬链接是有着相同inode号仅文件名不同的文件,因此硬链接存在以下几个特性:
- 文件有着相同的inode及data block;
- 智能对已存在的文件进行创建
- 不能价差文件系统进行硬链接的穿件
- 不能对目录进行创建,只可对 文件创建
- 删除一个硬链接文件,并不影响其他有着相同inode号的文件。
软连接(字符链接)
软连接的连接文件默认指的是字符连接文件,使用I表示其类型。
软连接在功能上等价于windows的快捷方式,他只想原文件,源文件算怀或消失,软连接文件就损坏。
与硬链接不同的是,每一个软链接文件有单独的inode和block data,只不过其数据块里面的储存的是指向原文件inode的指针。
下面一张图可以表明两种链接的区别:
inode的直接和间接寻址
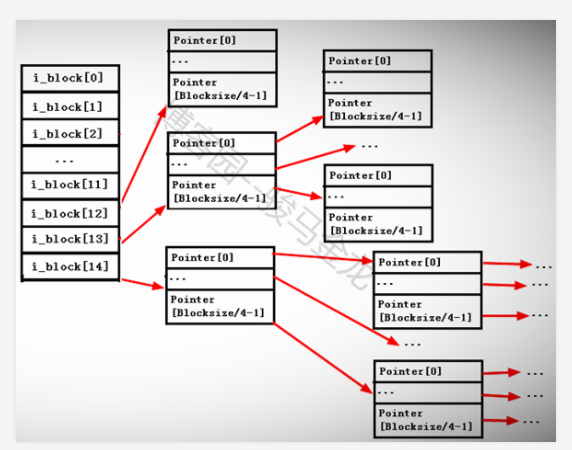
这个直接和简介寻址的概念是操作系统中常用的用于扩展寻址范围的方法。inode中保存的是blocks的指针,但是一条inode记录中能保存的指针数量有限,如果是十分大的文件,一个inode无法保存文件指向的所有数据块,则引入了间接寻址的盖帘。
在ext2和ext3的文件系统中,一个inode中最多只能有15个指针,前12个指针直接寻址,指向datablock,13个指针为一级间接寻址,它指向一个仍然存储了指针的data block,第14和15个指针分别为2级寻址和三级寻址。
如图所示:
上面总结了ext文件系统的组成,下面实例剖析一下ext文件系统之间更新的功能
ext3文件系统日志功能
相比于ex2文件系统,ext3多了一个日志功能。在ext2文件系统中,只有两个区:数据区和元数据区。如果正在向data block中填充数据时突然断电,那么下一次启动时就会检查文件系统中数据和状态的一致性,这段检查和修复可能会消耗大量时间,甚至检查后无法修复。之所以会这样是因为文件系统在突然断电后,它不知道上次正在存储的文件的block从哪里开始、哪里结束,所以它会扫描整个文件系统进行排除(也许是这样检查的吧)。
而在创建ext3文件系统时会划分三个区:数据区、日志区和元数据区。每次存储数据时,先在日志区中进行ext2中元数据区的活动,直到文件存储完成后标记上commit才将日志区中的数据转存到元数据区。当存储文件时突然断电,下一次检查修复文件系统时,只需要检查日志区的记录,将bmap对应的data block标记为未使用,并把inode号标记未使用,这样就不需要扫描整个文件系统而耗费大量时间。
相当于给文件储存过程中增加了一个缓冲区。
ext4文件系统在寻址上优化
ext3和ext2文件系统都是用直接寻址和间接寻址的方式,对于三级间接指针,可能要遍历的指针数量是非常巨大的。
ext4文件系统最大的特点是在ext3的基础上使用区(extent)的盖帘来进行管理,一个extent尽可能的包含物理上连续的一对block。inode寻址方面也一样使用区段树的方式进行了改进。默认情况下,EXT4不再使用EXT3的block mapping分配方式 ,而改为Extent方式分配。
(1). 关于EXT4的结构特征
EXT4在总体结构上与EXT3相似,大的分配方向都是基于相同大小的块组,每个块组内分配固定数量的inode、可能的superblock(或备份)及GDT。
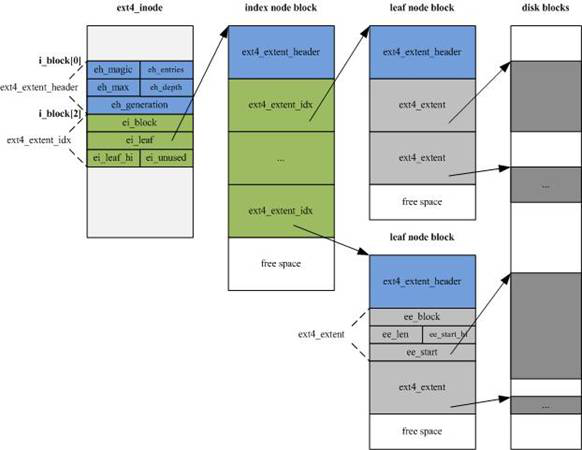
EXT4的inode 结构做了重大改变,为增加新的信息,大小由EXT3的128字节增加到默认的256字节,同时inode寻址索引不再使用EXT3的”12个直接寻址块+1个一级间接寻址块+1个二级间接寻址块+1个三级间接寻址块”的索引模式,而改为4个Extent片断流,每个片断流设定片断的起始block号及连续的block数量(有可能直接指向数据区,也有可能指向索引块区)。
片段流即下图中索引节点(inde node block)部分的绿色区域,每个15字节,共60字节。
(2). EXT4删除数据的结构更改。
EXT4删除数据后,会依次释放文件系统bitmap空间位、更新目录结构、释放inode空间位。
(3). ext4使用多block分配方式。
在存储数据时,ext3中的block分配器一次只能分配4KB大小的Block数量,而且每存储一个block前就标记一次bmap。假如存储1G的文件,blocksize是4KB,那么每存储完一个Block就将调用一次block分配器,即调用的次数为10241024/4KB=262144次,标记bmap的次数也为10241024/4=262144次。
而在ext4中根据区段来分配,可以实现调用一次block分配器就分配一堆连续的block,并在存储这一堆block前一次性标记对应的bmap。这对于大文件来说极大的提升了存储效率。
ext类文件系统的缺点
最大的缺点是它在创建文件系统的时候就划分好一切需要划分的东西,以后用到的时候可以直接进行分配,也就是说它不支持动态划分和动态分配。对于较小的分区来说速度还好,但是对于一个超大的磁盘,速度是极慢极慢的。