设计模式—策略,桥接,观察者
个人感觉设计模式虽然是概念,但是研究代码的组成可能跟容易理解
Author:Zreal
参考https://design-patterns.readthedocs.io/zh_CN/latest/index.html 图说设计模式
策略模式(strategy)
动机:
现在要写一个sort函数,我们要sort函数集成多种不同的排序算法,要怎么写才能构成高效的结构
模式定义
定义一些列算法,将每个算法封装起来,并让他们可以相互替换。策略模式让算法独立与使用它的客户而变化。
模式结构
类图:
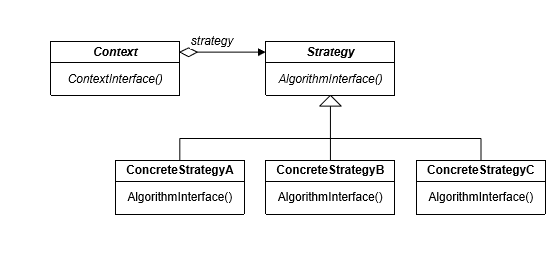
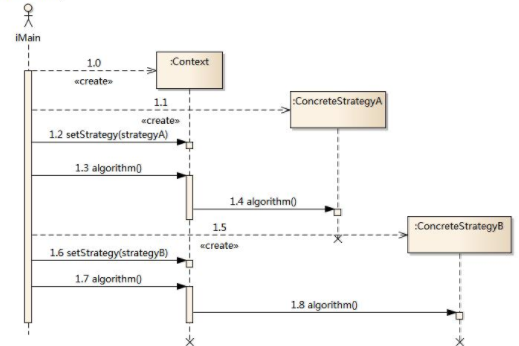
时序图:
Context:应用strategy对象并为strategy对象提供接口
strategy:一个抽象类,声明所有算法的通用接口。context接口调用concretestrategy实现算法
concretestrategy:实现strategy的算法接口
代码分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
//Context 类
class Context
{
public:
Context();
virtual ~Context();
void algorithm();
void setStrategy(Strategy* st);
private:
Strategy *m_pStrategy;
};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
//Context 类实现
#include "Context.h"
Context::Context(){
}
Context::~Context(){
}
void Context::algorithm(){
m_pStrategy->algorithm();
}
void Context::setStrategy(Strategy* st){
m_pStrategy = st;
}
1
2
3
4
5
6
7
8
9
10
11
//具体的a策略,是Strategy抽象类的子类,Strategy抽象类定义了algorithm()接口,a类必须重写覆盖这个函数。
class ConcreteStrategyA : public Strategy
{
public:
ConcreteStrategyA();
virtual ~ConcreteStrategyA();
virtual void algorithm();
};
1
2
3
4
5
6
7
8
9
10
11
12
13
#include "ConcreteStrategyA.h"
#include <iostream>
using namespace std;
ConcreteStrategyA::ConcreteStrategyA(){
}
ConcreteStrategyA::~ConcreteStrategyA(){
}
void ConcreteStrategyA::algorithm(){
cout << "use algorithm A" << endl;
}
调用顺序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#include <iostream>
#include "Context.h"
#include "ConcreteStrategyA.h"
#include "ConcreteStrategyB.h"
#include "Strategy.h"
#include <vector>
using namespace std;
int main(int argc, char *argv[])
{
Strategy * s1 = new ConcreteStrategyA();
//先new一个自己需要的排序算法的对象
Context * cxt = new Context();
cxt->setStrategy(s1);
//context 将其set为自己的属性
cxt->algorithm();
//通过接口调用 ConreteStrategyA里面的algorithm()
Strategy *s2 = new ConcreteStrategyB();
cxt->setStrategy(s2);
cxt->algorithm();
return 0;
}
模式分析:
策略模式仅仅封装算法,提供新算法插入到已有系统中,以及老算法从系统中“退休”的方便,策略模式并不决定在何时使用何种算法,算法的选择由客户端来决定。这在一定程度上提高了系统的灵活性,但是客户端需要理解所有具体策略类之间的区别,以便选择合适的算法,这也是策略模式的缺点之一,在一定程度上增加了客户端的使用难度。
桥接模式(bridge)
刚开始的时候感觉桥接模式和策略模式十分类似,桥接模式也相对复杂。但是弄清楚他们动机之间的区别,就很容易理解两种设计模式在使用和定义上的区别了。
桥模式的动机:
设想如果要绘制矩形、圆形、椭圆、正方形,我们至少需要4个形状类,但是如果绘制的图形需要具有不同的颜色,如红色、绿色、蓝色等,此时至少有如下两种设计方案:
- 第一种设计方案是为每一种形状都提供一套各种颜色的版本。
- 第二种设计方案是根据实际需要对形状和颜色进行组合
对于有两个变化维度(即两个变化的原因)的系统,采用方案二来进行设计系统中类的个数更少,且系统扩展更为方便。设计方案二即是桥接模式的应用。桥接模式将继承关系转换为关联关系,从而降低了类与类之间的耦合,减少了代码编写量。
可以看到策略模式的动机是,现在我要使用排序但是我现在有很多种算法可以选择。选择的特征上只有算法这一个维度。怎样去编码符合NFR原则
而桥模式是,现在有两个维度的特征,既要选择用怎样的算法实现排序,又要选择排序对象的类型是字符串还是整形。怎样才能简单的将两种维度的特征实现组合。重点是组合。
类图:
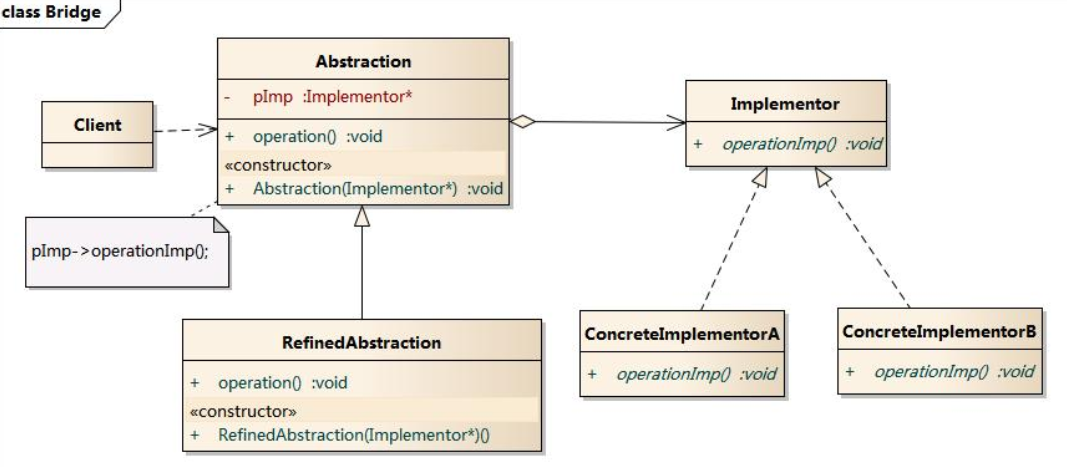
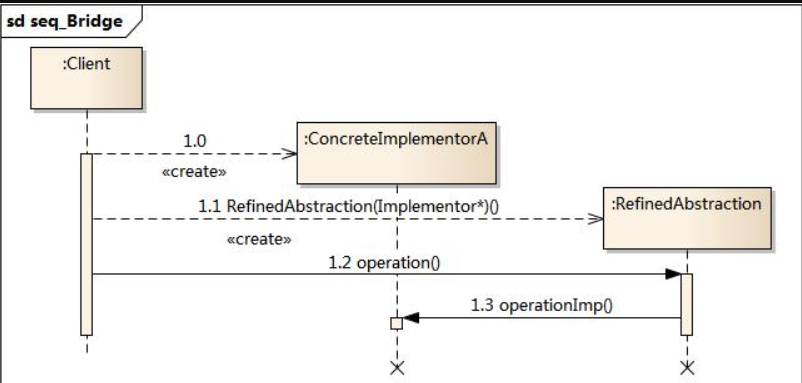
时序图:
- Abstraction:抽象类
- RefinedAbstraction:扩充抽象类
- Implementor:实现类接口
- ConcreteImplementor:具体实现类
个人认知:
实现类接口和具体实现类与策略模式中的相似,代表一个维度的特点,现在的抽象类和扩充抽象类。抽象类代表这一类对象的接口,扩充抽象类,代表另一个维度的特点的不同种的实现类。(还是没说清楚,直接举例子)
以操作系统和计算机为例子,计算机上有不同的操作系统,同时计算机本身的品牌也不相同。此时计算机就是Abstraction抽象类,惠普计算机就是扩充抽象类,操作系统是实现类的接口,苹果操作系统是具体实现类。
UML图:
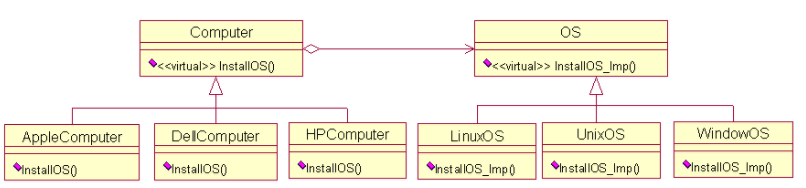
代码层级实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
//操作系统
class OS
{
public:
virtual void InstallOS_Imp() {}
};
class WindowOS: public OS
{
public:
void InstallOS_Imp() { cout<<"安装Window操作系统"<<endl; }
};
class LinuxOS: public OS
{
public:
void InstallOS_Imp() { cout<<"安装Linux操作系统"<<endl; }
};
class UnixOS: public OS
{
public:
void InstallOS_Imp() { cout<<"安装Unix操作系统"<<endl; }
};
//计算机
class Computer
{
public:
virtual void InstallOS(OS *os) {}
};
class DellComputer: public Computer
{
public:
void InstallOS(OS *os) { os->InstallOS_Imp(); }
};
class AppleComputer: public Computer
{
public:
void InstallOS(OS *os) { os->InstallOS_Imp(); }
};
class HPComputer: public Computer
{
public:
void InstallOS(OS *os) { os->InstallOS_Imp(); }
};
客户使用方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int main()
{
OS *os1 = new WindowOS();
OS *os2 = new LinuxOS();
//首先先创建一个实现类
Computer *computer1 = new AppleComputer();
//再创建一个扩展抽象类型
computer1->InstallOS(os1);
computer1->InstallOS(os2);
//实现类作为参数,扩展抽象类型的调用方法,即将广义上两种特征进行了组合。
/*
还有另外一种实现方法,在扩展抽象类型中声明一个实现类接口,添加一个set方法,用于改变这 个实现类接口,对其赋值为具体实现类,然后InstallOS函数就无需传入参数,这样写进一步减少了对 象之间的耦合。
*/
}
模式优点:
-
分离抽象类及其实现部分
- 桥接模式有时类似于多继承方案,但是多继承方案违背了类的单一职责原则(即一个类只有一个变化的原因),复用性比较差,而且多继承结构中类的个数非常庞大,桥接模式是比多继承方案更好的解决方法。
- 桥接模式提高了系统的可扩充性,在两个变化维度中任意扩展一个维度,都不需要修改原有系统。
- 实现细节对客户透明,可以对用户隐藏实现细节。
模式缺点:
- 桥接模式的引入会增加系统的理解与设计难度,由于聚合关联关系建立在抽象层,要求开发者针对抽象进
行设计与编程。 - 桥接模式要求正确识别出系统中两个独立变化的维度,因此其使用范围具有一定的局限性。
观察者模式(observer)
定义
定义一个对象和多个对象之间的1对多的依赖关系,使得当一个一个对象的状态发生变化时,所有依赖者都被自动通知并更新状态。
动机
当把系统分解为多个协同类是,副作用是需维护相关对象的一致性
你不希望通过增加耦合度来获得一致性,那样会降低可复用性
类图:
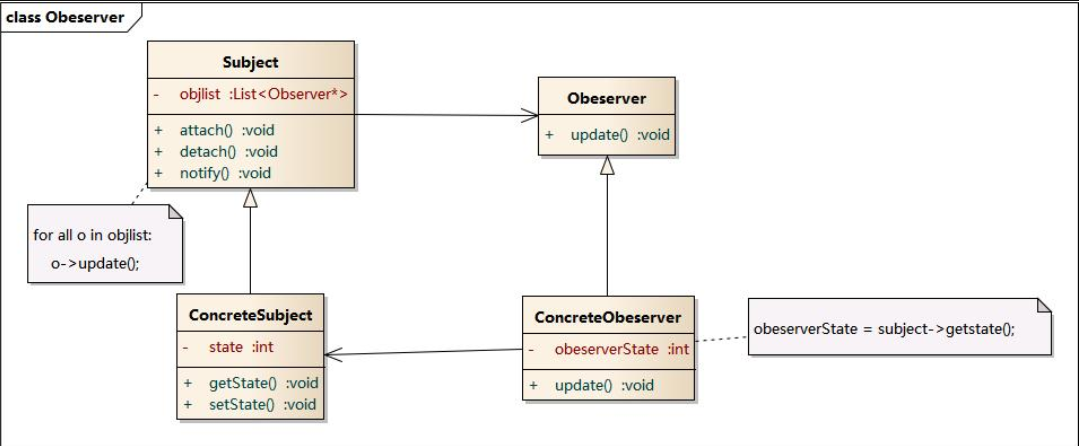
时序图:
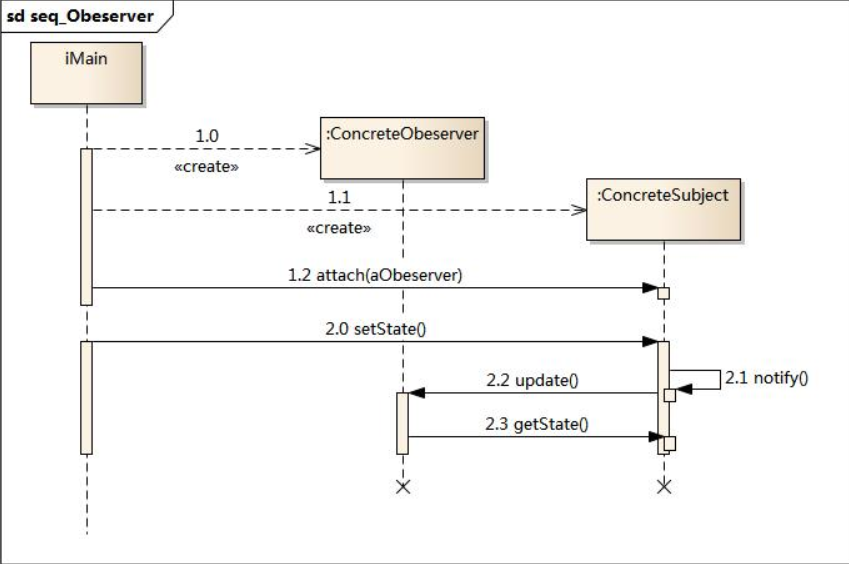
代码分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
//Subject 抽象类
#include <vector>
using namespace std;
class Subject
{
public:
Subject();
virtual ~Subject();
Obeserver *m_Obeserver;
//连接观察者
void attach(Obeserver * pObeserver);
//去观察者
void detach(Obeserver * pObeserver);
//通知观察者
void notify();
//子类必须重写的两个函数,获得状态,设置状态;
virtual int getState() = 0;
virtual void setState(int i)= 0;
private:
vector<Obeserver*> m_vtObj;
//所有的观察这个对象的观察者用一个vector进行维护
};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
//Subject 函数实现
Subject::Subject(){
}
Subject::~Subject(){
}
//将观察者加入队列
void Subject::attach(Obeserver * pObeserver){
m_vtObj.push_back(pObeserver);
}
//在队列中找到该观察者,剔出队列
void Subject::detach(Obeserver * pObeserver){
for(vector<Obeserver*>::iterator itr = m_vtObj.begin();
for(;itr != m_vtObj.end(); itr++)
{
if(*itr == pObeserver)
{
m_vtObj.erase(itr);
return;
}
}
}
//对观察者队列进行遍历,调用观察者的update()方法更新其状态
void Subject::notify(){
for(vector<Obeserver*>::iterator itr = m_vtObj.begin();
itr != m_vtObj.end();
itr++)
{
(*itr)->update(this);
}
}
观察者类:
1
2
3
4
5
6
7
8
class Obeserver
{
public:
Obeserver();
virtual ~Obeserver();
//子类必须重写update 方法
virtual void update(Subject * sub) = 0;
}
观察者实例:
1
2
3
4
5
6
7
8
9
10
11
12
class ConcreteObeserver : public Obeserver
{
public:
ConcreteObeserver(string name);
virtual ~ConcreteObeserver();
virtual void update(Subject * sub);
private:
string m_objName;
int m_obeserverState;
};
方法实现:
1
2
3
4
5
6
7
8
9
10
11
12
ConcreteObeserver::ConcreteObeserver(string name){
m_objName = name;
}
ConcreteObeserver::~ConcreteObeserver(){
}
//被观察者作为参数传入,调用getState 获取状态,更新观察者状态
void ConcreteObeserver::update(Subject * sub){
m_obeserverState = sub->getState();
cout << "update oberserver[" << m_objName << "] state:" << m_obeserverState << endl;
}
执行顺序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
int main(int argc, char *argv[])
{
Subject * subject = new ConcreteSubject();
Obeserver * objA = new ConcreteObeserver("A");
Obeserver * objB = new ConcreteObeserver("B");
subject->attach(objA);
subject->attach(objB);
subject->setState(1);
subject->notify();
cout << "--------------------" << endl;
subject->detach(objB);
subject->setState(2);
subject->notify();
delete subject;
delete objA;
delete objB;
return 0;
}
优点
- 观察者模式可以实现表示层和数据逻辑层的分离,并定义了稳定的消息更新传递机制,抽象了更新接口,使得可以有各种各样不同的表示层作为具体观察者角色。
- 观察者模式在观察目标和观察者之间建立一个抽象的耦合。
- 观察者模式支持广播通信。
- 观察者模式符合“开闭原则”的要求。
缺点
- 如果一个观察目标对象有很多直接和间接的观察者的话,将所有的观察者都通知到会花费很多时间。
- 如果在观察者和观察目标之间有循环依赖的话,观察目标会触发它们之间进行循环调用,可能导致系统崩溃。
- 观察者模式没有相应的机制让观察者知道所观察的目标对象是怎么发生变化的,而仅仅只是知道观察目标发生了变化。